-
2016-03-31 19:50:24更新於 2017-03-04 14:48:03
最近學C、C++,想一塊學,因為大學程式的緣故,我想,我還是先修好了,練習演算法,順便複習以前的程式。我已經語法大混亂了,沒有編譯器糾正我,基本很難寫正確程式,除非最近都在攻某個專案,否則我平時都是一天寫好幾種不同語言的程式,函數偶爾會亂調用。我知道有些工程師很討厭什麼語言都碰一點的人,但,我不管啦,我就是什麼都學,反正最後我也只會主攻少數幾項,也不至於什麼語言都很淺。
|
Python | PHP | JS | |
if state:
#do sth
elif state:
#do sth
else:
#do sth | if(state){
//do sth
}elseif(state){
//do sth
}else{
//do sth
} | if(state){
//do sth
}else
if(state){
//do sth
}else{
//do sth
} | |
for x in range(0,10):
#do sth |
for($i=0;$i<10;$i++){
//do sth
} |
for(var i=0;i<10;i++){
//do sth
} | |
for k in arr:
#do sth | foreach ($arr as
$value) {
//do sth
} | for(var key in arr){
//value=arr[key];
} | |
| Not Exist | switch($mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} | switch(mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} | |
def foo(v1,v2):
return sth | function
foo($v1,$v2){
return sth;
}
//call by
reference
function foo(&$v1,&$v2){
return
sth;
} | function foo(v1,v2){
return sth;
} | |
| Java | C# | C | C++ |
if(state){
//do sth
}else if(state){
//do sth
}else{
//do sth
} |
if(state){
//do sth
}else if(state){
//do sth
}else{
//do sth
} |
if(state){
//do sth
}else if(state){
//do sth
}else{
//do sth
} |
if(state){
//do sth
}else if(state){
//do sth
}else{
//do sth
} |
for(int i=0;i<10;i++){
//do sth
} |
for(int i=0;i<10;i++){
//do sth
} |
for(i=0;i<10;i++){
//do sth
} |
for(i=0;i<10;i++){
//do sth
} |
for(int k : arr){
//do sth
} |
foreach (int k in arr){
//do sth
} | Not
Exist | for(int k : arr){
//do sth
} |
switch(mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} | switch(mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} | switch(mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} | switch(mod){
case 1:
//do sth
break;
case 2:
//do sth
break;
default:
//do sth
} |
public int foo(int v1, int v2){
return sth;
} | public int foo(int v1, int v2){
return sth;
}
//call by reference
public int foo(ref
int v1, ref int v2){
return sth;
}
foo(ref a,ref b);
public int foo(out int v1, out int v2){
return sth;
}
foo(out a,out b); | int foo(int v1, int
v2){
return sth;
}
//call by reference
int foo(int *v1, int *v2){
//調用引數都要加*
return sth;
}
foo(&a,&b); | int foo(int v1, int v2){
return sth;
}
//call by reference
int foo(int &v1, int
&v2){
return sth;
}
foo(a,b);
//call by pointer
int foo(int *v1, int *v2){
//調用所有引數都要加*
return sth;
}
foo(&a,&b); |
WeilsNetLogo
This entry was posted in C#, C, C++, Java, JS, PHP, Python By Weil Jimmer .
.
-
2016-03-27 15:09:41更新於 2017-05-19 18:53:20
鑒於網站上的空間有限,存放圖片又非常不方便,存本站會耗費空間與流量,存外站就不會。而 Flickr 支持 1 TB 的免費圖片空間!還支援原圖外連,這對我來說,非常好用!
為了把外站同步相簿到本站,需要研讀一下 Flickr API ,請參考:
https://www.flickr.com/services/api/
由於本教學是不需要"簽發授權的",所以原圖只能是上傳者公開,才能取得,否則只能其他解析度的圖片。但拿不到原圖,基本上還是很高清的。
不然只能用Flickr的OAuth取得Token,不過太麻煩我就不講了。可以參考:
https://www.flickr.com/services/api/explore/flickr.photosets.getPhotos

必須要自己設定成公開,API才可以取得原始圖片。
第一步、要先建立應用程式,https://www.flickr.com/services/apps/create/apply/
隨便填一下資料後,可以取得 應用程式的 key 值與金鑰。
然後使用:http://idgettr.com/
輸入自己個人頁面網址,可以取得 自己的 User ID,長得像是: 123456789@N01。
接著用「程式」訪問 Flickr 的 API 特殊網址 (要記得變更網址 { } 大括號夾住部分):
API_KEY,USER_ID 請照上述步驟取得
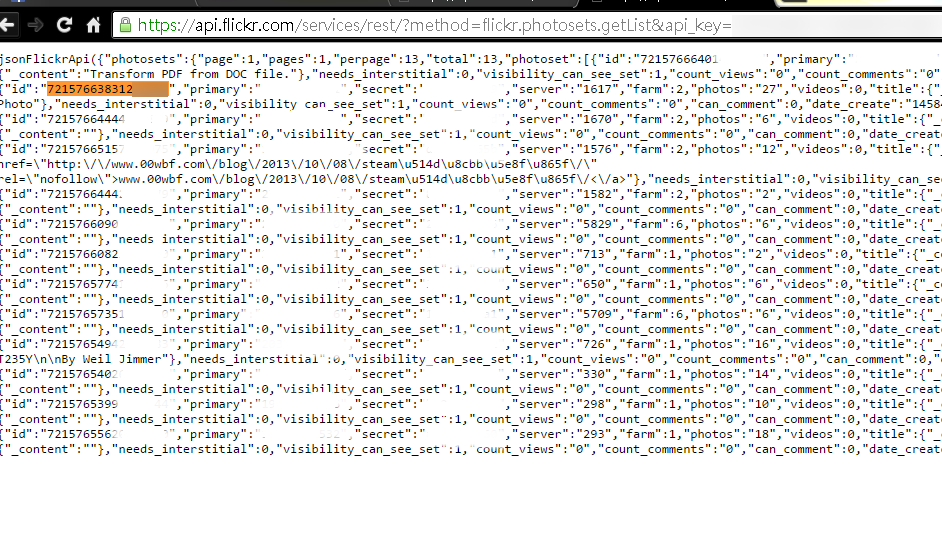
https://api.flickr.com/services/rest/?method=flickr.photosets.getList&api_key={API_KEY}&user_id={USER_ID}&format=json
可以得到如下圖的頁面:這是JSON格式的資料。請尋找您要取得網址的相簿ID。(長得像是下圖橘色所示)
然後再用程式訪問
{API_KEY},{USER_ID},{PHOTOSET_ID}記得替換
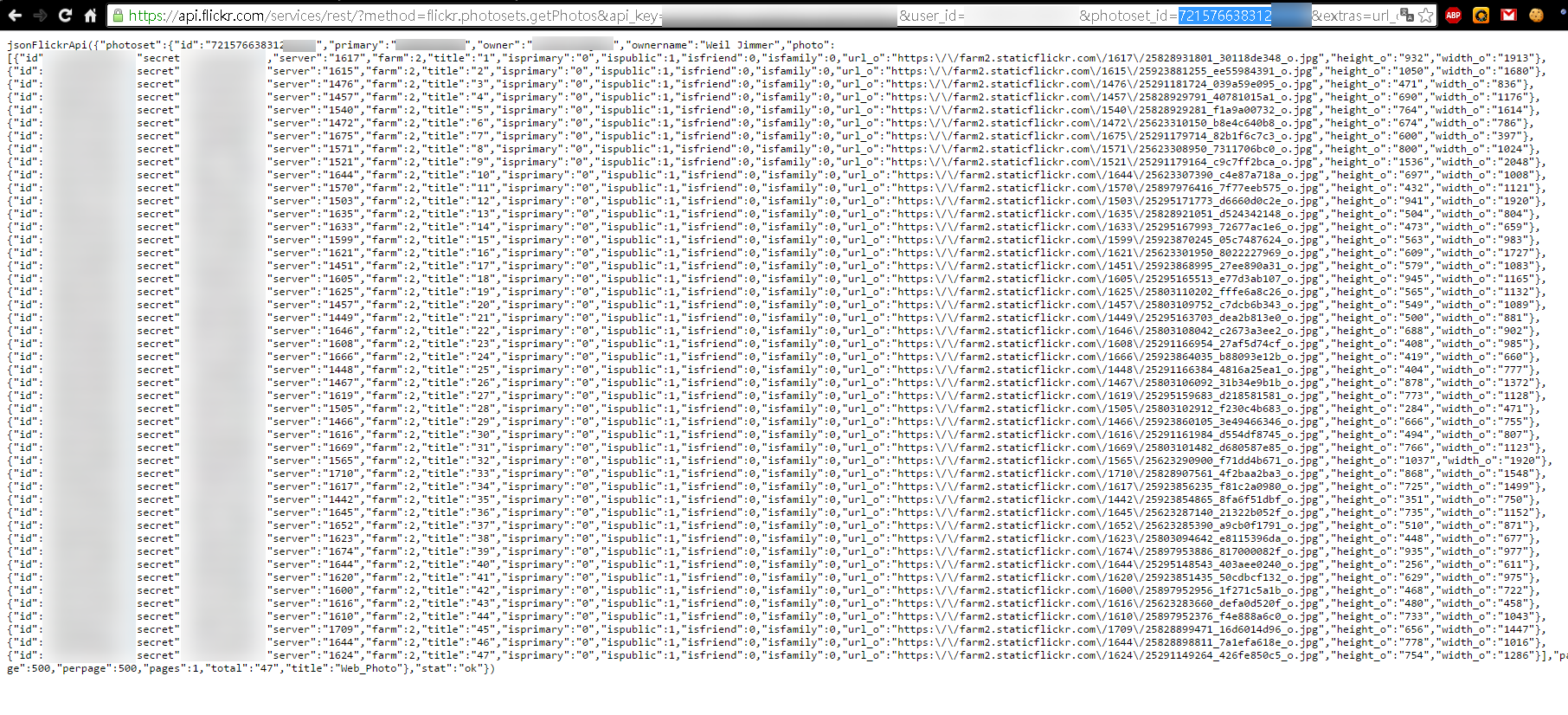
https://api.flickr.com/services/rest/?method=flickr.photosets.getPhotos&api_key={API_KEY}&user_id={USER_ID}&photoset_id={PHOTOSET_ID}&extras=url_o&format=json
就可取得 原始 資料。
範例程式碼:
<textarea name="contents" id="contents" style="resize:vertical;height:150px;font-size:12pt;"></textarea>
<script type="text/javascript">
var http = new XMLHttpRequest("Microsoft.XMLHTTP");
var url_='https://api.flickr.com/services/rest/?method=flickr.photosets.getPhotos&api_key={API_KEY}&user_id={USER_ID}&photoset_id={PHOTOSET_ID}&extras=url_o&format=json';
function connect(){
http.onreadystatechange = function(){
if (http.readyState==4){
if (http.status==200){
var str = http.responseText.toString();
str = str.substring(14,str.length-1);
var obj = JSON.parse(str);
var html_code_to_load = "";
for (var i=0;i<obj['photoset']['photo'].length;i++){
html_code_to_load += obj['photoset']['photo'][i]['url_o'] + "\n";
}
document.getElementById('contents').innerHTML=html_code_to_load.substring(0,html_code_to_load.length-1);
}else{
//Connect Failed.
}
}
}
http.open("GET",url_,true);
http.send();
}
connect();
</script>

WeilsNetLogo
This entry was posted in General, Experience, Functions, HTML, JS, XML By Weil Jimmer.
-
2016-03-26 22:10:35更新於 2017-02-18 23:12:52
使用內建的 Office 即可做轉換!
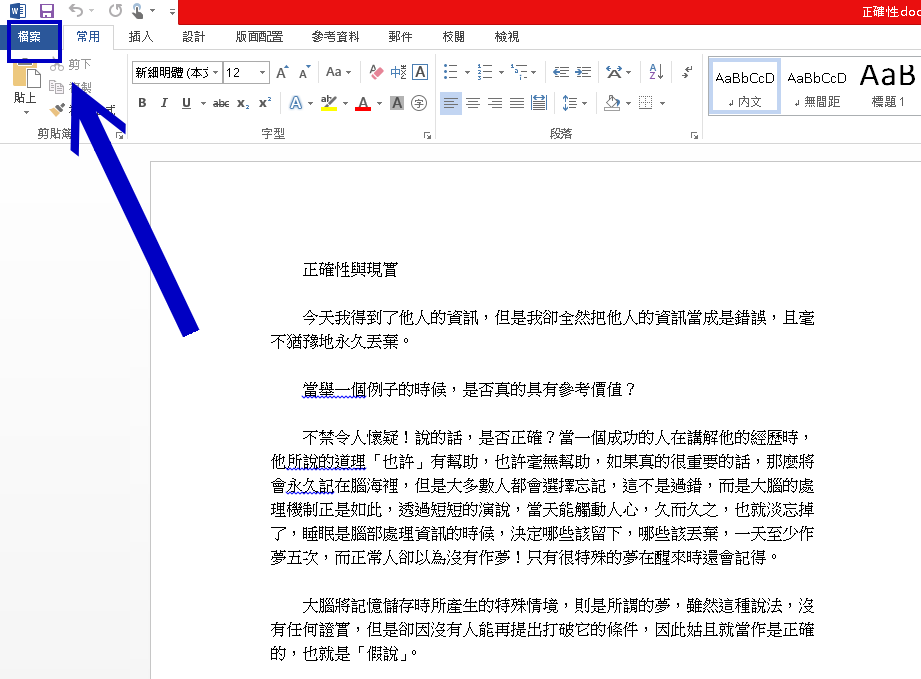
第一步,開啟文件並點擊左上角的檔案。
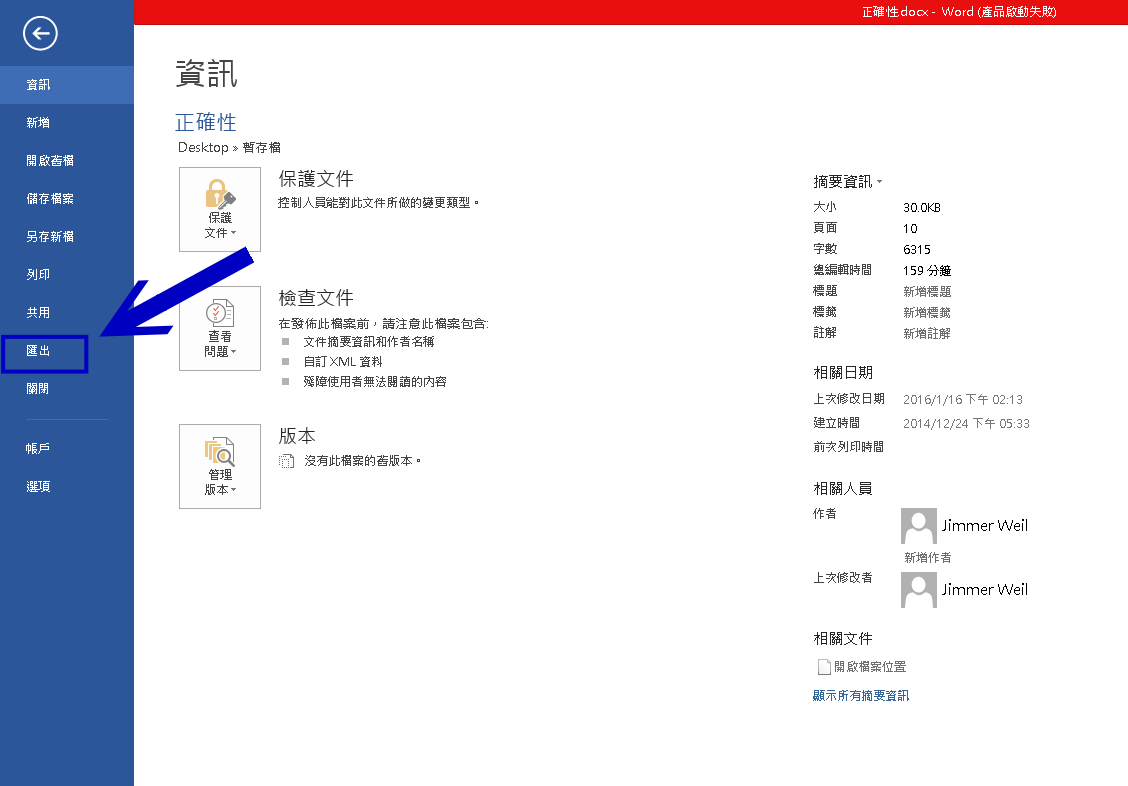
然後選擇側欄的「匯出」,
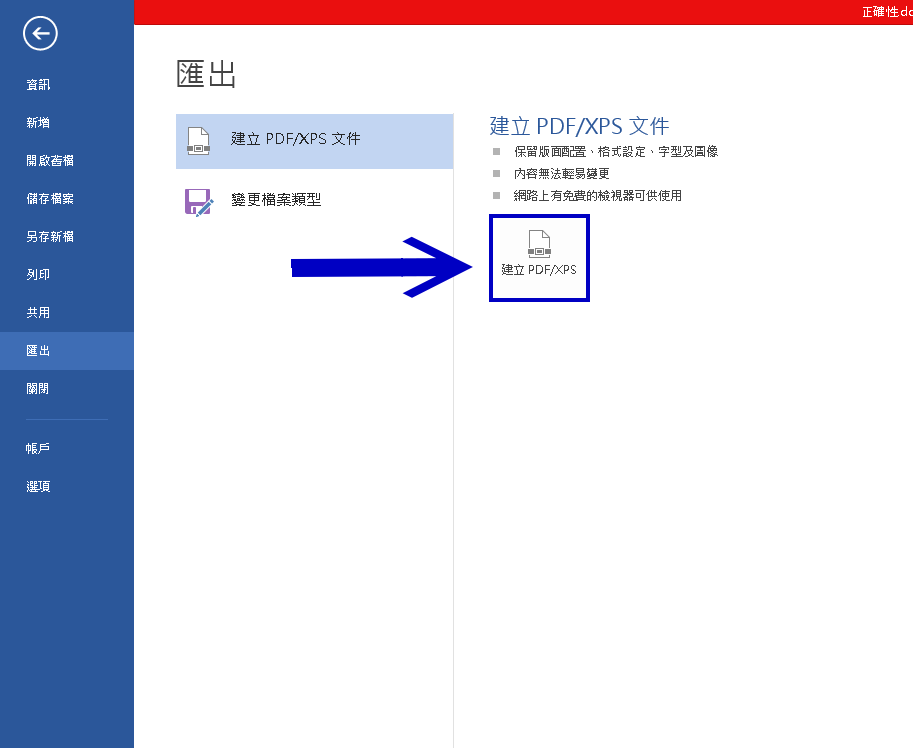
接著點擊「建立PDF/XPS」的按鈕,
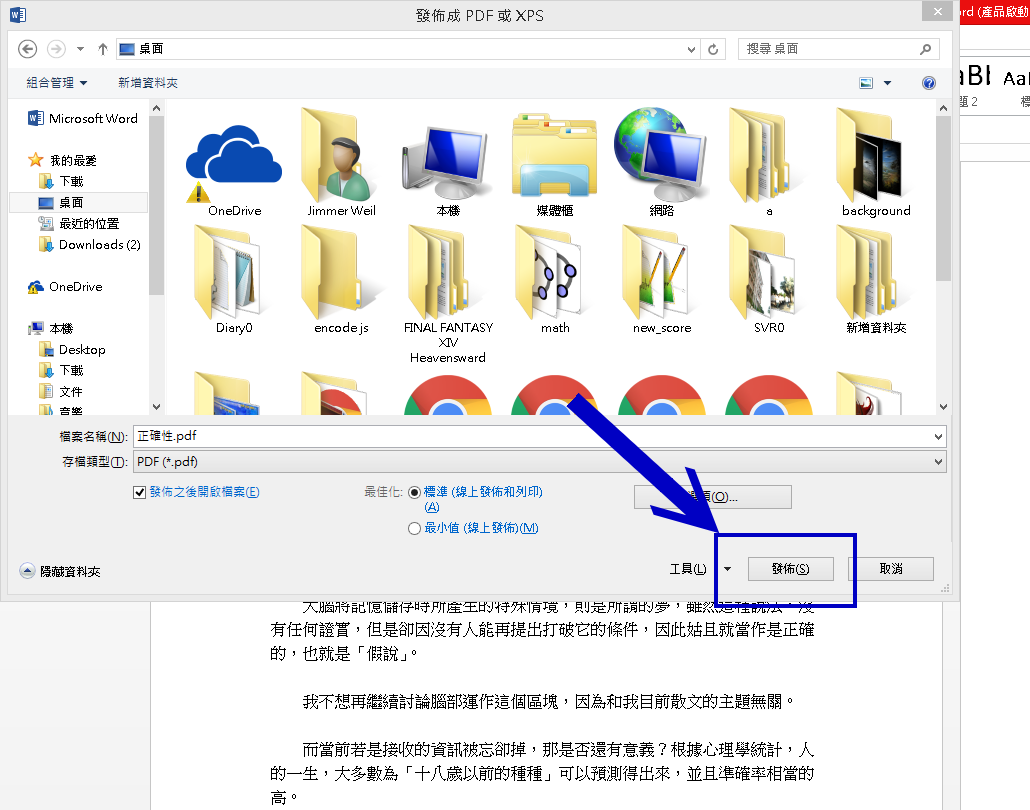
存檔!
就完成了轉換。
WeilsNetLogo
This entry was posted in Experience, Office By Weil Jimmer.
-
發布於 2016-03-14 22:12:032016-03-14 22:12:03
因為最近移轉了主機,甚至買了域名和SSL證書,覺得非常接近理想狀態中的好網站,我也很想用心經營,不過,即使換了穩定主機,我卻不知道要發表什麼文章好……
因為本人是高中生,近來面臨升學壓力,一方面要顧著資訊領域,一方面要顧課業,而發文的此刻,我早就已經被通知錄取了中後段的國立大學,現在面臨著一堆煩惱,尤其是家中的負擔,我希望我可以在大學時就可以馬上工作支付我的學費,不過看來應該是不可能的事情。
各種心情參雜,加上今天是一個特別的日子,唯有聽我收藏的鋼琴曲可以稍微解悶而已。
WeilsNetLogo
This entry was posted in Mood By Weil Jimmer.
-
2016-02-25 18:25:08更新於 2017-03-04 14:49:16
- 本站自2016.02.22日起正式搬遷其域名由0000.twgogo.org更替為www.00wbf.com。
- 並且更換網站主機為專屬虛擬主機。若您還依舊使用舊網域者,請更新您的網址,謝謝。
- 本站今年5月9日至5月12日遭受DDOS巨大攻擊,導致下線,造成困擾,請見諒!
###2017.02.27-更新-###
本站最新之域名為:weils.net
WeilsNetLogo
This entry was posted in Announcement, General By Weil Jimmer.






 Linode
Linode





{kind=link}