Category:Free
Found 13 records. At Page 1 / 3.
-
2018-05-27 16:34:05更新於 2020-02-07 15:50:52
This entry was posted in Android, General, Software, Free, Java, Product, Tools By Weil Jimmer .
.
-
發布於 2018-05-01 11:55:082018-05-01 11:55:08
This entry was posted in Android, General, Software, Free, Product By Weil Jimmer.
-
2018-01-25 17:47:10更新於 2018-01-26 19:19:41
This entry was posted in C#, Software, Free, Product, Tools By Weil Jimmer.
-
2017-01-10 21:35:16更新於 2023-01-08 21:03:00

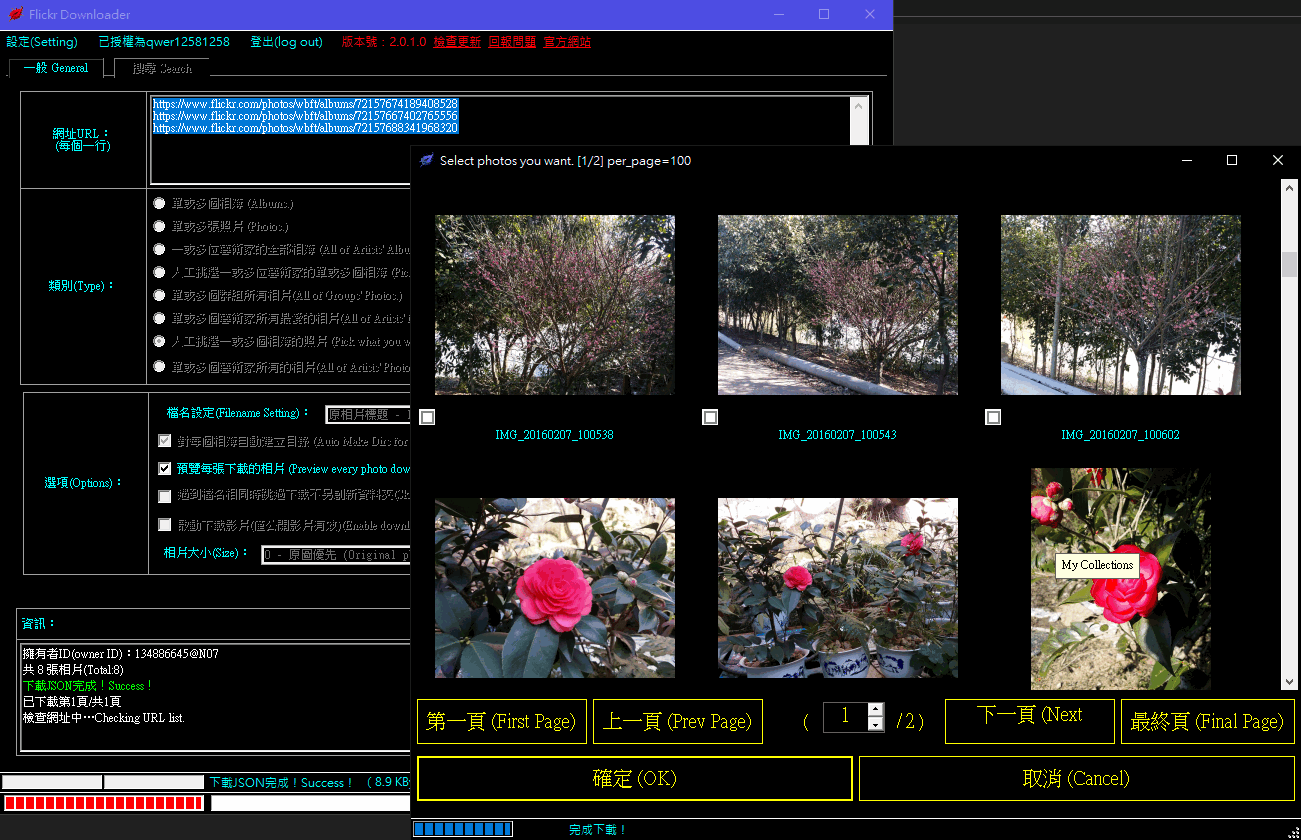
本程式可以批量下載 Flickr 網站上的圖片,主要功能為:
- 一、批量下載多個相簿內的所有照片。
- 二、批量下載多張相片。
- 三、批量下載多位藝術家的全部相簿裡的圖片。
- 四、由多位藝術家的相簿中人工挑選相簿並下載相簿內全部相片。
- 五、由多位藝術家的相簿中人工挑選相片並下載。
- 六、批量下載多個群組的所有相片。
- 七、批量下載多個藝術家的所有最愛的相片。
- 八、批量下載多個藝術家的所有上傳的相片。
- 九、可以選擇下載的照片大小,以及登入授權帳號就可以透過程式下載私密群組(您已加入)的照片,或是下載您設為私密的相片。
- 十、搜尋相片並人工挑選方式批量下載。
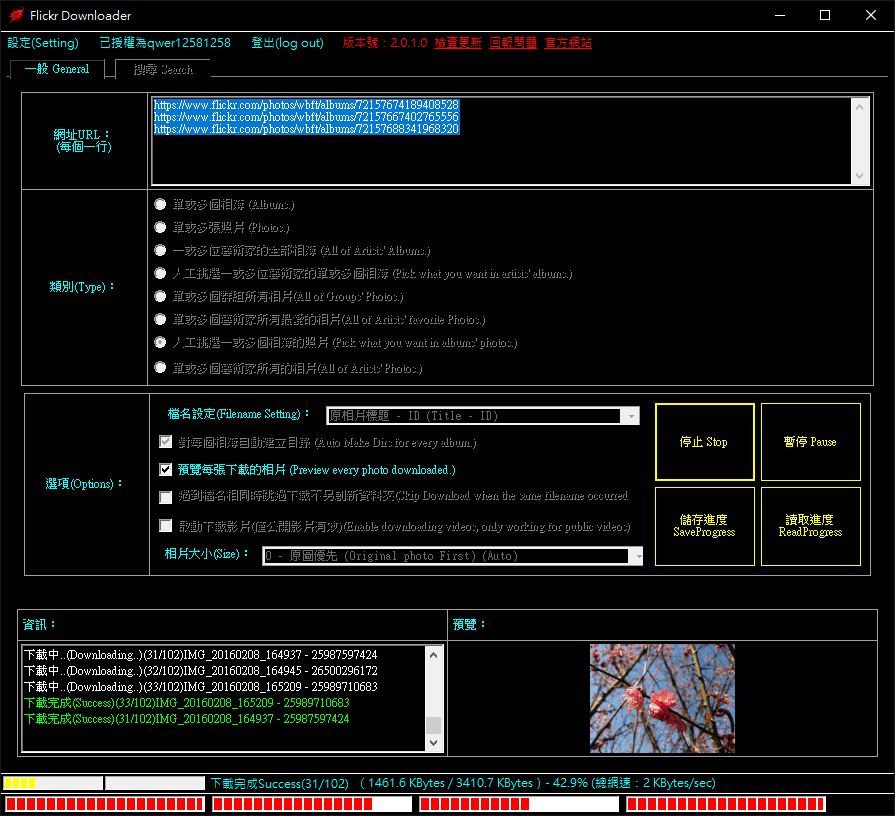
本程式可選擇「自動命名&創建資料夾做分類」、亦可下載照片全部集中在同個資料夾,以及針對每張照片以原標題命名或以數字化命名或相片ID或拍攝日期…等,下載時不會因為名稱重複而覆蓋掉。
另外,本程式可以儲存下載進度,預防下載不完可以改天繼續下載,以及可以自訂背景顏色、文字顏色、按鈕顏色、音效、線程數,自訂是否縮小化退出程式。
下載地址【一】:https://url.weils.net/n
下載地址【二】:https://url.weils.net/r
產品連結:http://web.wbftw.org/product/flickrdownloader
兼容作業系統:Win XP / Win 7 / Win 8 / Win8.1 / Win 10 (64bit or 32bit) 需安裝 .Net Framework 4.0 以上的版本以執行程式。
[本應用程式已不再維護][點此查看原始碼]
===省略部分更新日誌,請前往產品網站檢視。===
WeilsNetLogo
This entry was posted in C#, General, Software, Free, Product, Tools By Weil Jimmer.
-
2016-05-01 17:57:17更新於 2017-11-17 00:52:47
This entry was posted in General, Software, Free, Product By Weil Jimmer.









 Linode
Linode





{kind=link}