Category:General
Found 67 records. At Page 9 / 14.
-
發布於 2016-04-25 20:16:502016-04-25 20:16:50
最近不知道要發什麼,這篇這是純當筆記用。
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $data);
if (stripos($data,'https://')===0){
//網址是https,設定SSL。
curl_setopt($ch, CURLOPT_SSLVERSION,CURL_SSLVERSION_DEFAULT);
curl_setopt($ch,CURLOPT_SSL_VERIFYHOST,0);
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,0);
}
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36');
curl_setopt($ch, CURLOPT_MAXREDIRS, 999);
$html = curl_exec($ch);
$header_size = curl_getinfo($ch, CURLINFO_HEADER_SIZE);
$header = substr($html, 0, $header_size);
$html_body = substr($html, $header_size);
curl_close($ch);
WeilsNetLogo
This entry was posted in General, Functions, The Internet, Note, PHP By Weil Jimmer .
.
-
2016-04-06 22:04:08更新於 2017-10-11 21:43:51
此方法已過時!請勿使用!未來將會可能重新更新此文章!
首先,這個方法透過不少外國管道!請別擔心。
此方法僅提供一個讓你透過超商繳費的方法可以付款用於大多數線上網站。
第一步先註冊BitoEx的帳號:https://www.bitoex.com
註冊帳號是為了購買全球通用的國際虛擬貨幣比特幣。
而比特幣可以在 BitoEx 購買到。建議購買至少 500 NT$。(可全家超商繳費付款,目前只能"全家"!)
買比特幣教學參考:https://www.bitoex.com/fami?locale=zh-tw
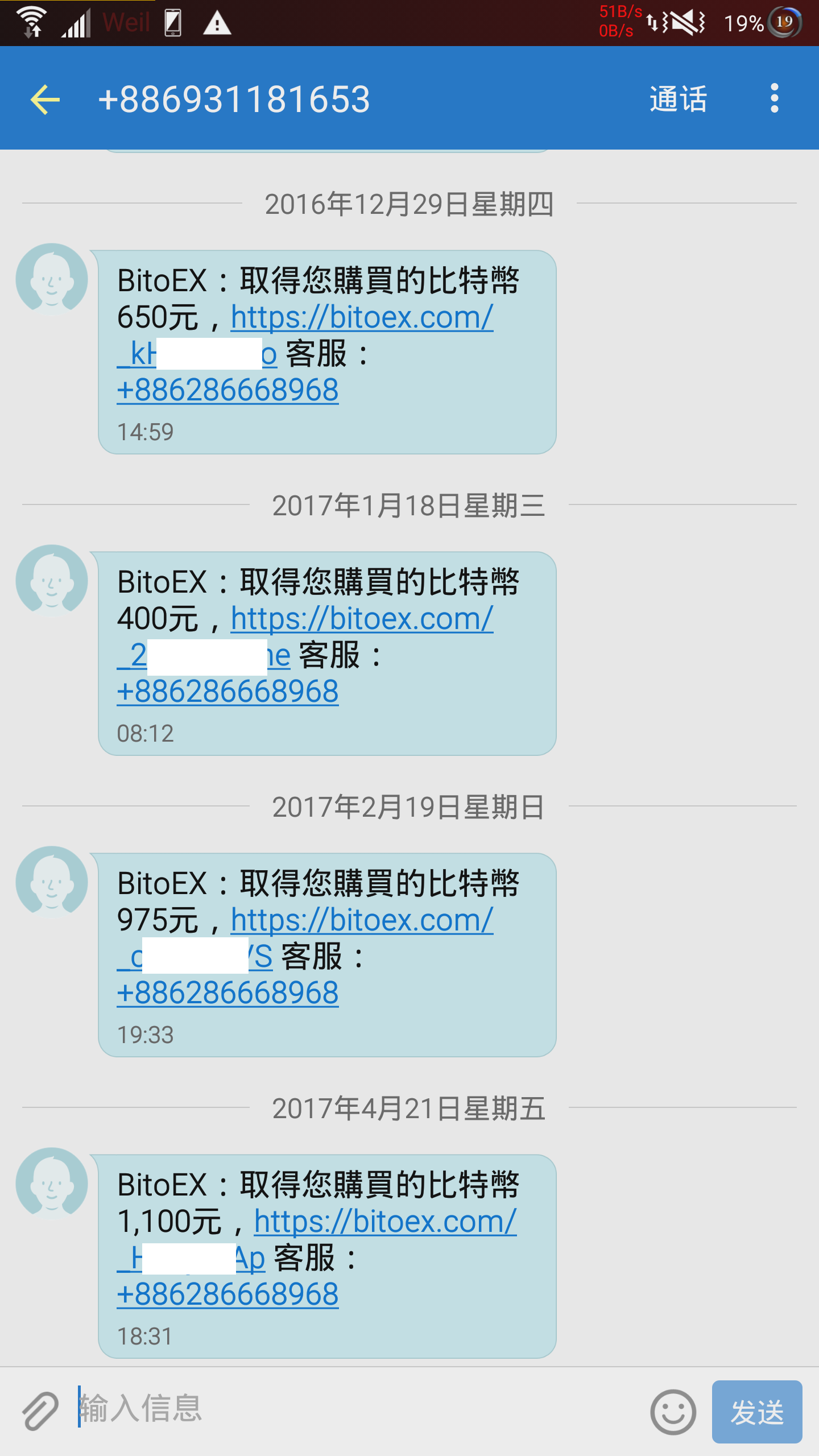
購買完成之後,通常會收到簡訊。如下:

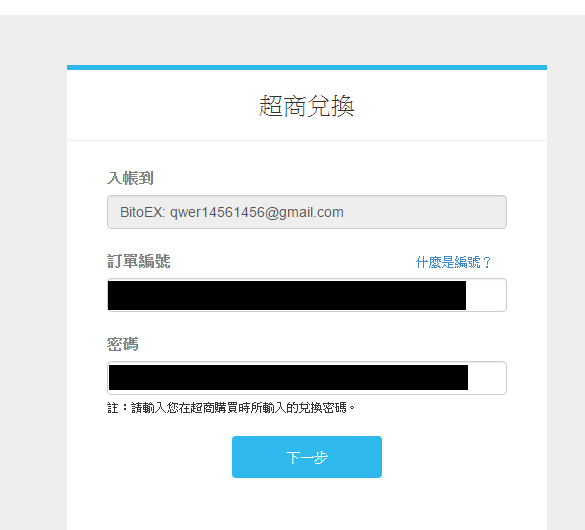
然後,請先開好瀏覽器,登入進去BitoEx,接著點手機裡收到的連結。依照指示儲金額進入BitoEx。
兌換到我的錢包就可以了!(畫面僅供參考)
然後就去 Cryptopay 註冊帳號:https://cryptopay.me/join/f526d895
(使用上面的連結買金融卡可以打 75 折。)
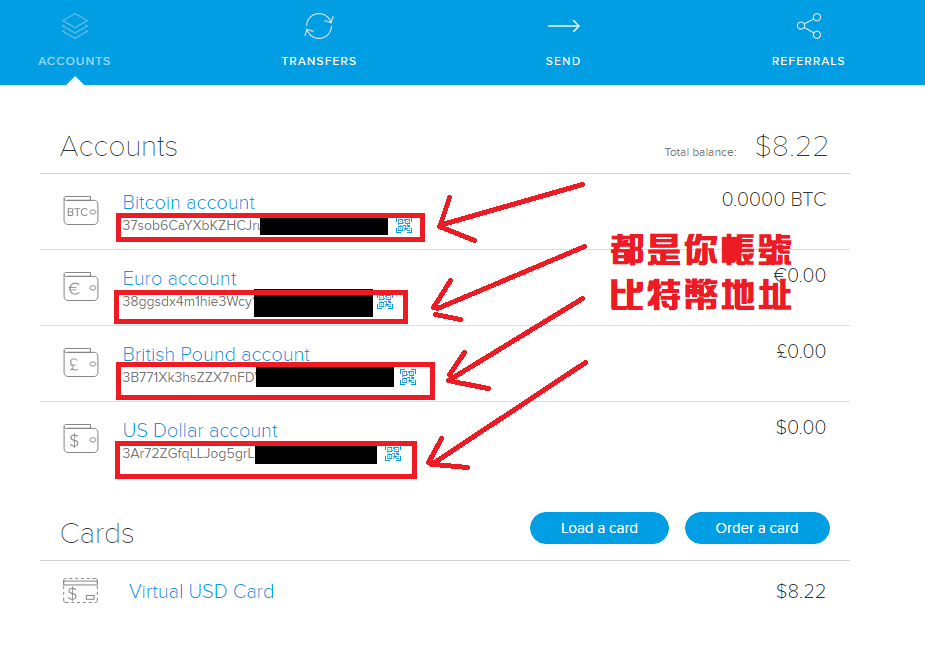
註冊好帳號後,記得驗證 Email,然後登入,就會看到如下介面。
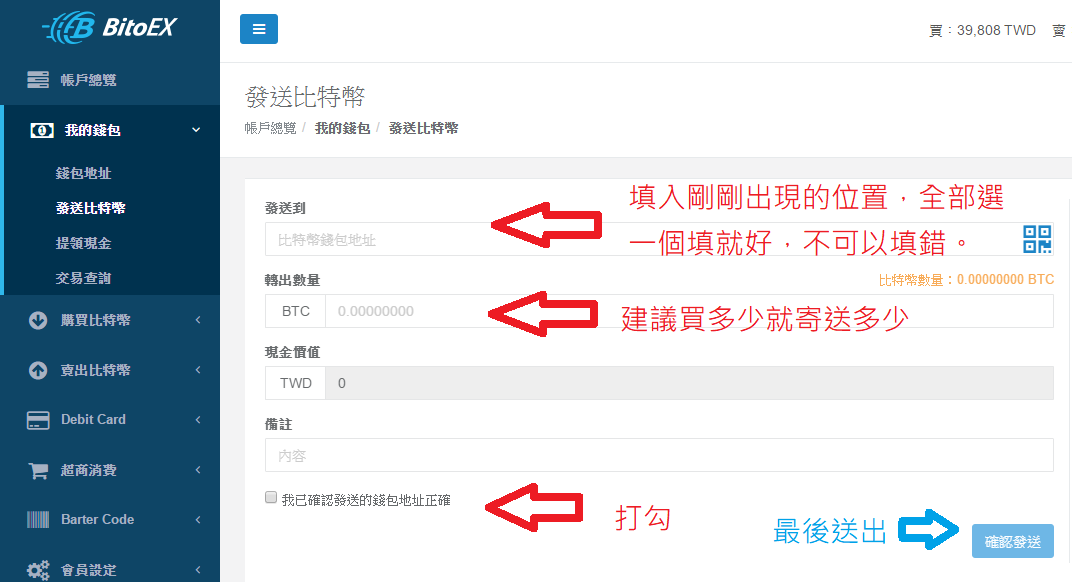
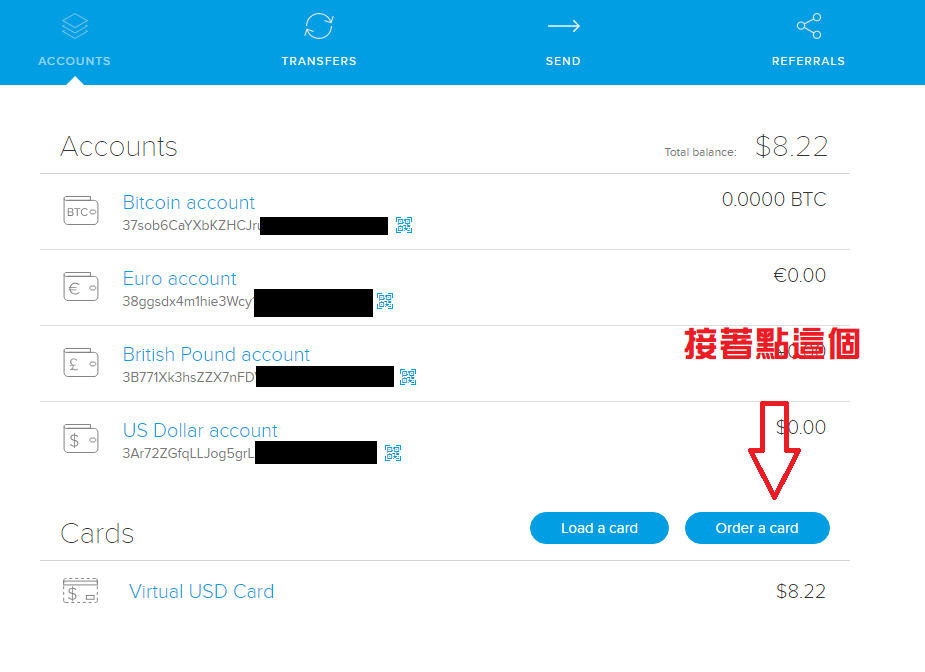
這四組比特幣地址都是你自己帳號的錢,只是貨幣單位不同,而且轉換過去後,就不會被比特幣價格升降而影響到幣值大小。建議直接複製 Bitcoin Account 的地址。之後要儲錢的話,可以直接寄到 USD Account。
就可以直接透過 BitoEx 寄送金額到這個國外網站。
這步驟!請注意!比特幣寄送的過程需要耗費十五分鐘至數小時,可能要等待很長一段時間才會入帳!
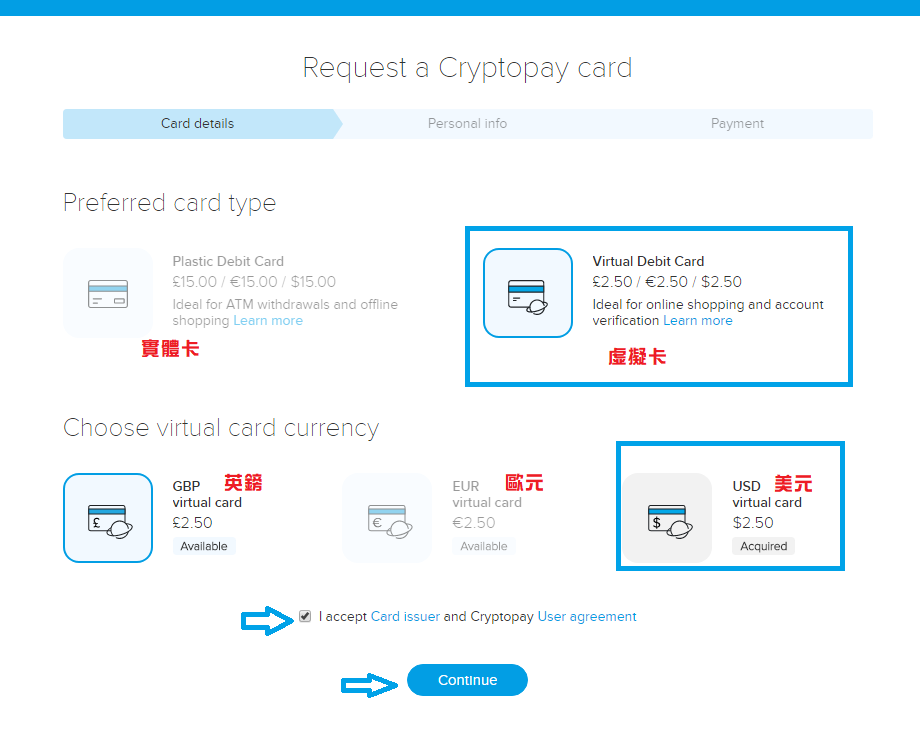
然後可以開始購買虛擬卡。
個人建議是買 USD 的虛擬卡拉,有其他需求就依照你自己的想法。
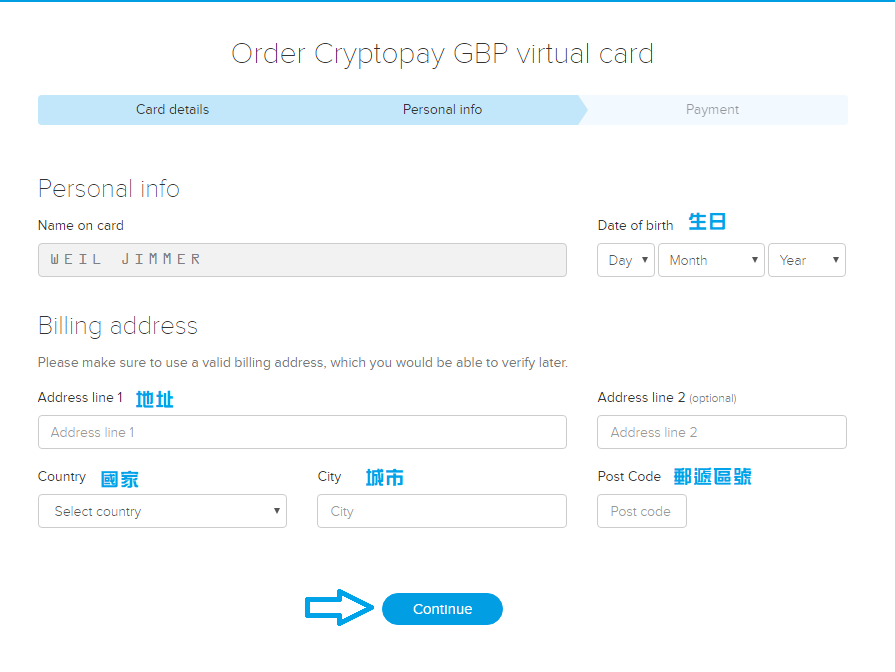
填入好基本資料後就可以送出了,基本上是可以亂填的。
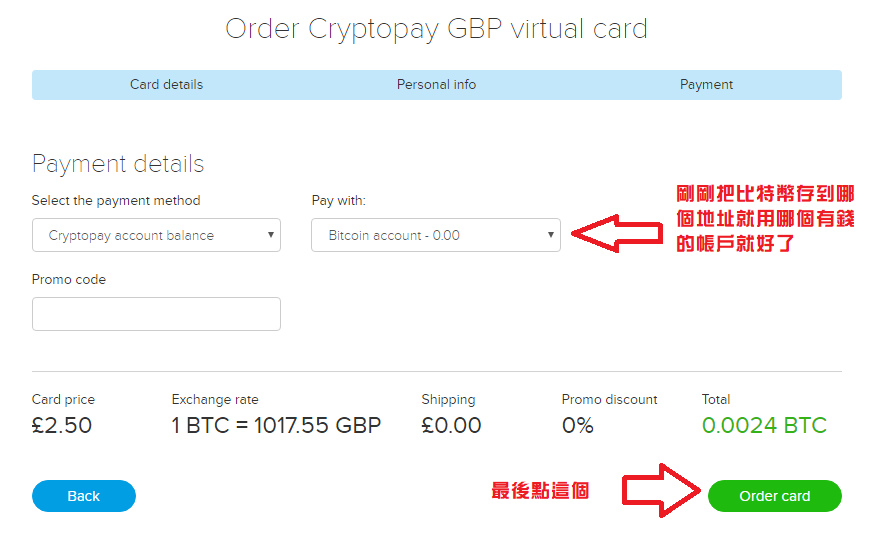
然後選擇剛剛儲進金額的 Bitcoin Account,除非你儲在別的地方,切換到有錢的帳號即可。
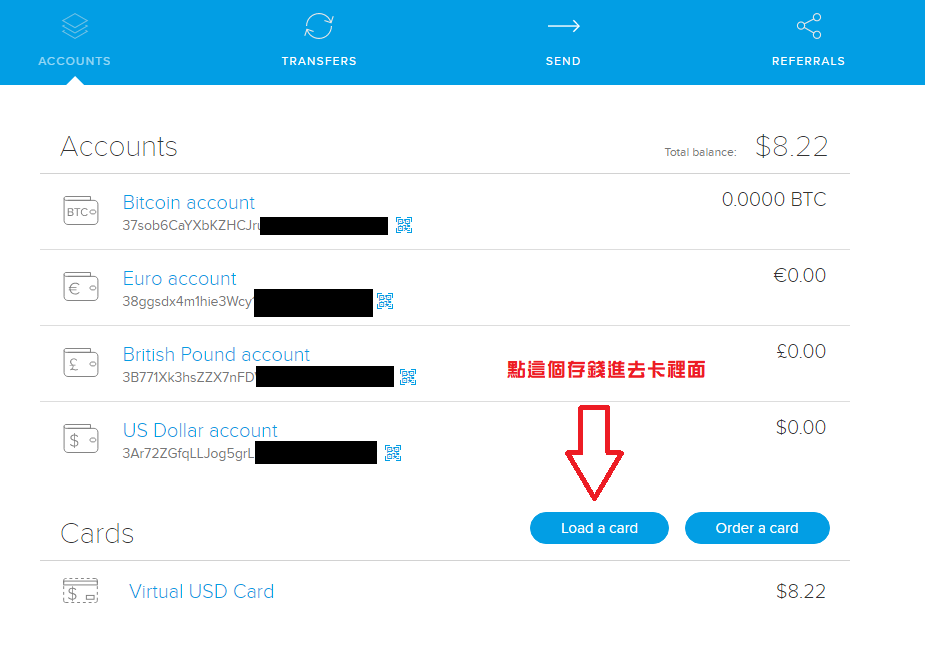
接著購買完成後,就可以正式來使用了。先儲錢進去虛擬卡。
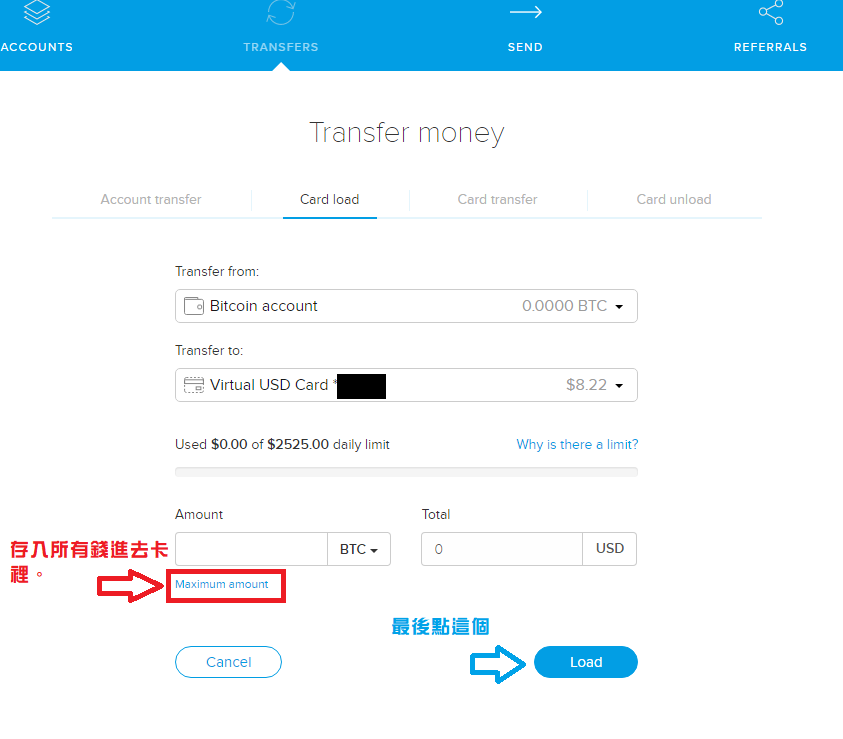
建議點 Maximum amount,直接儲最大金額,帳戶類別一樣要選有錢的帳戶,最後你就可以擁有比特幣的金融卡了!
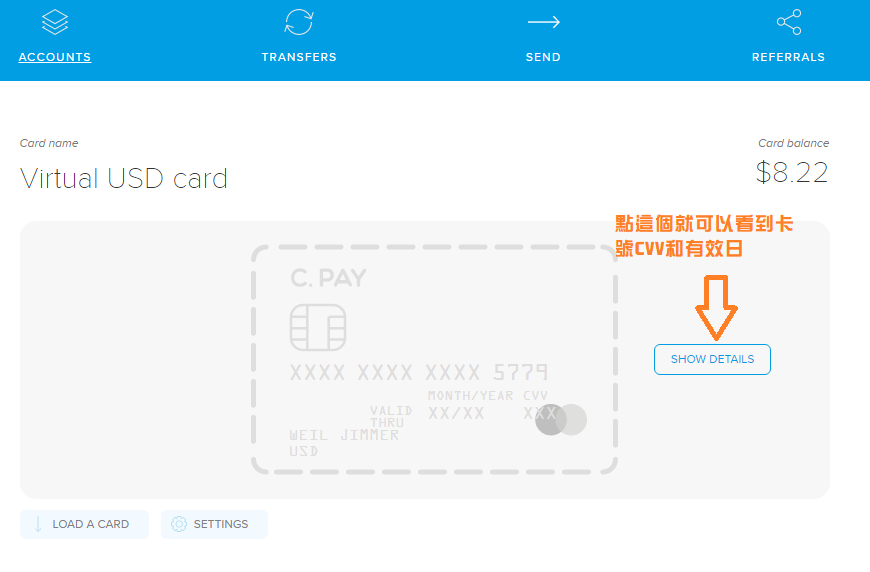
點那個按鈕可以知道你的卡號和安全碼及有效年月。
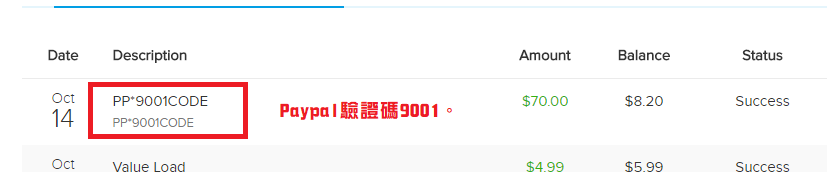
就會有紀錄在你的交易項目了!而那四位數字就是你的驗證碼。刷新Paypal,填入四位數字驗證碼就完成驗證了!
接著你就可以利用 Paypal進行匿名全球交易,而且只靠"超商繳費"與假身分。
最後我還是要說一件重要的事情,每個月維持卡的費用是1美金,以及這張卡有一些使用上限,可以參考:https://cryptopay.me/bitcoin-debit-card
基本上,使用上限是 2500 €/£/$ ,除非你驗證你的帳號,上傳身分驗證。
以上。

WeilsNetLogo
This entry was posted in General, Experience, Functions, The Internet, Note By Weil Jimmer.
-
2016-04-03 19:18:56更新於 2017-05-19 18:44:58
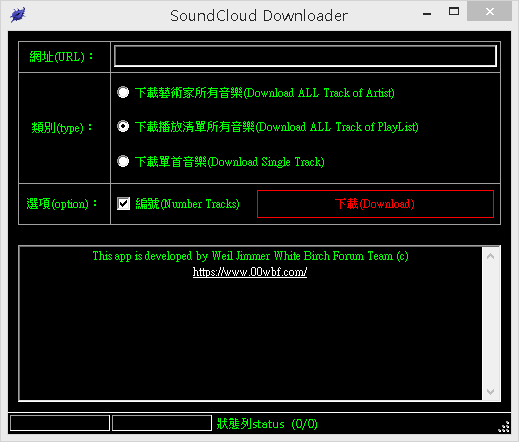
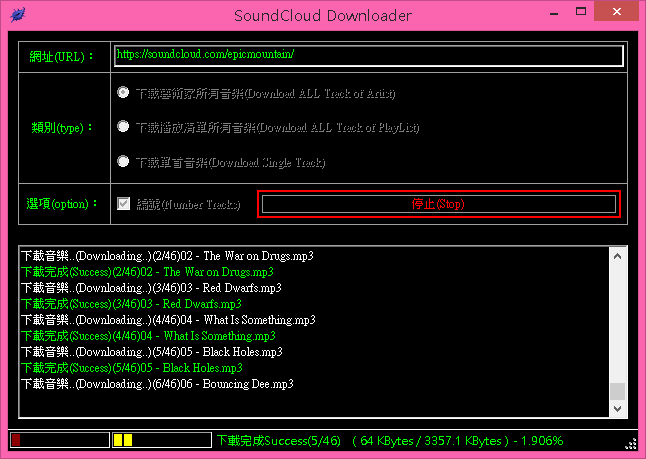
This entry was posted in General, Software, Free, The Internet, Product, Tools By Weil Jimmer.
-
2016-03-27 15:09:41更新於 2017-05-19 18:53:20
鑒於網站上的空間有限,存放圖片又非常不方便,存本站會耗費空間與流量,存外站就不會。而 Flickr 支持 1 TB 的免費圖片空間!還支援原圖外連,這對我來說,非常好用!
為了把外站同步相簿到本站,需要研讀一下 Flickr API ,請參考:
https://www.flickr.com/services/api/
由於本教學是不需要"簽發授權的",所以原圖只能是上傳者公開,才能取得,否則只能其他解析度的圖片。但拿不到原圖,基本上還是很高清的。
不然只能用Flickr的OAuth取得Token,不過太麻煩我就不講了。可以參考:
https://www.flickr.com/services/api/explore/flickr.photosets.getPhotos
必須要自己設定成公開,API才可以取得原始圖片。
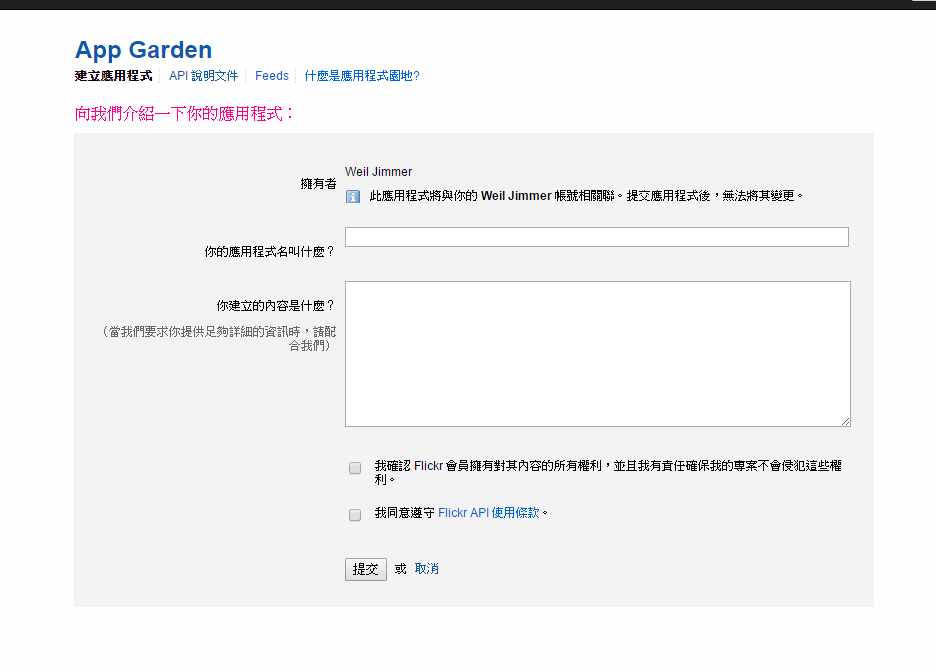
第一步、要先建立應用程式,https://www.flickr.com/services/apps/create/apply/
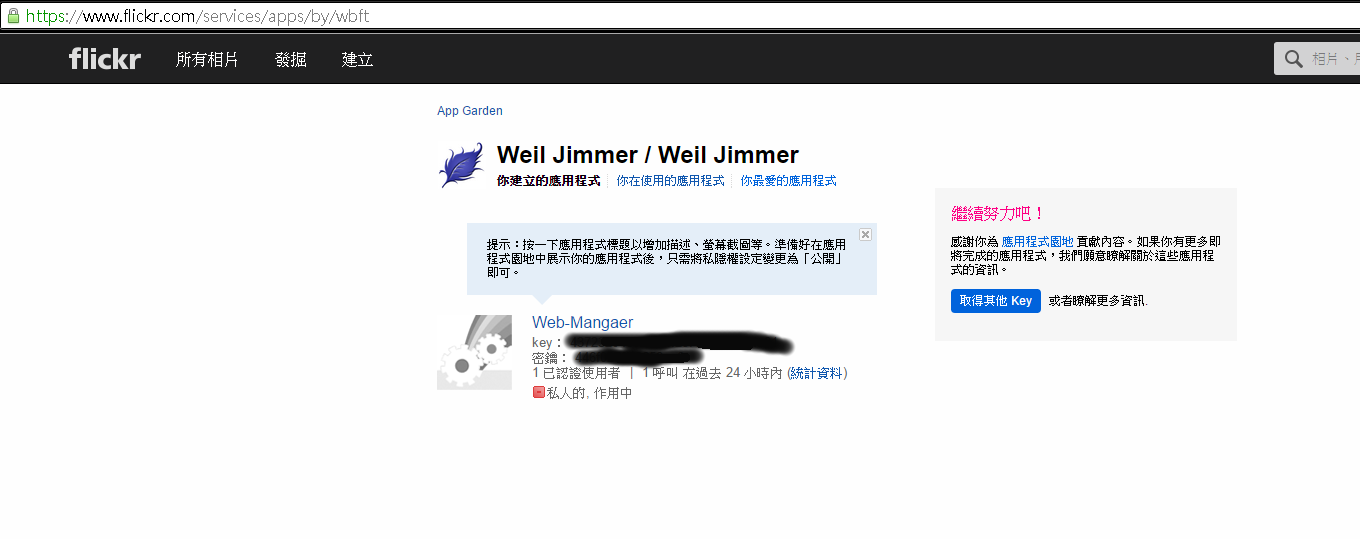
隨便填一下資料後,可以取得 應用程式的 key 值與金鑰。
然後使用:http://idgettr.com/
輸入自己個人頁面網址,可以取得 自己的 User ID,長得像是: 123456789@N01。
接著用「程式」訪問 Flickr 的 API 特殊網址 (要記得變更網址 { } 大括號夾住部分):
API_KEY,USER_ID 請照上述步驟取得
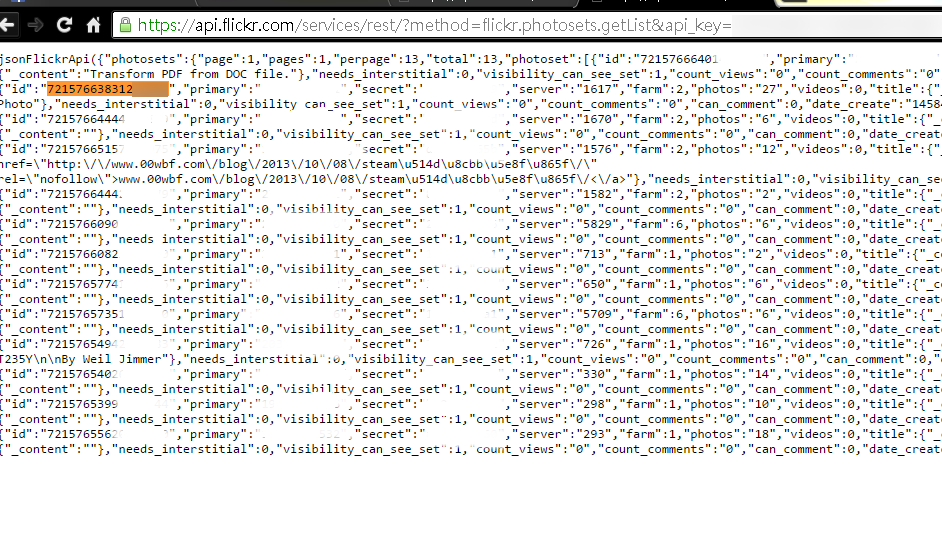
https://api.flickr.com/services/rest/?method=flickr.photosets.getList&api_key={API_KEY}&user_id={USER_ID}&format=json
可以得到如下圖的頁面:這是JSON格式的資料。請尋找您要取得網址的相簿ID。(長得像是下圖橘色所示)
然後再用程式訪問
{API_KEY},{USER_ID},{PHOTOSET_ID}記得替換
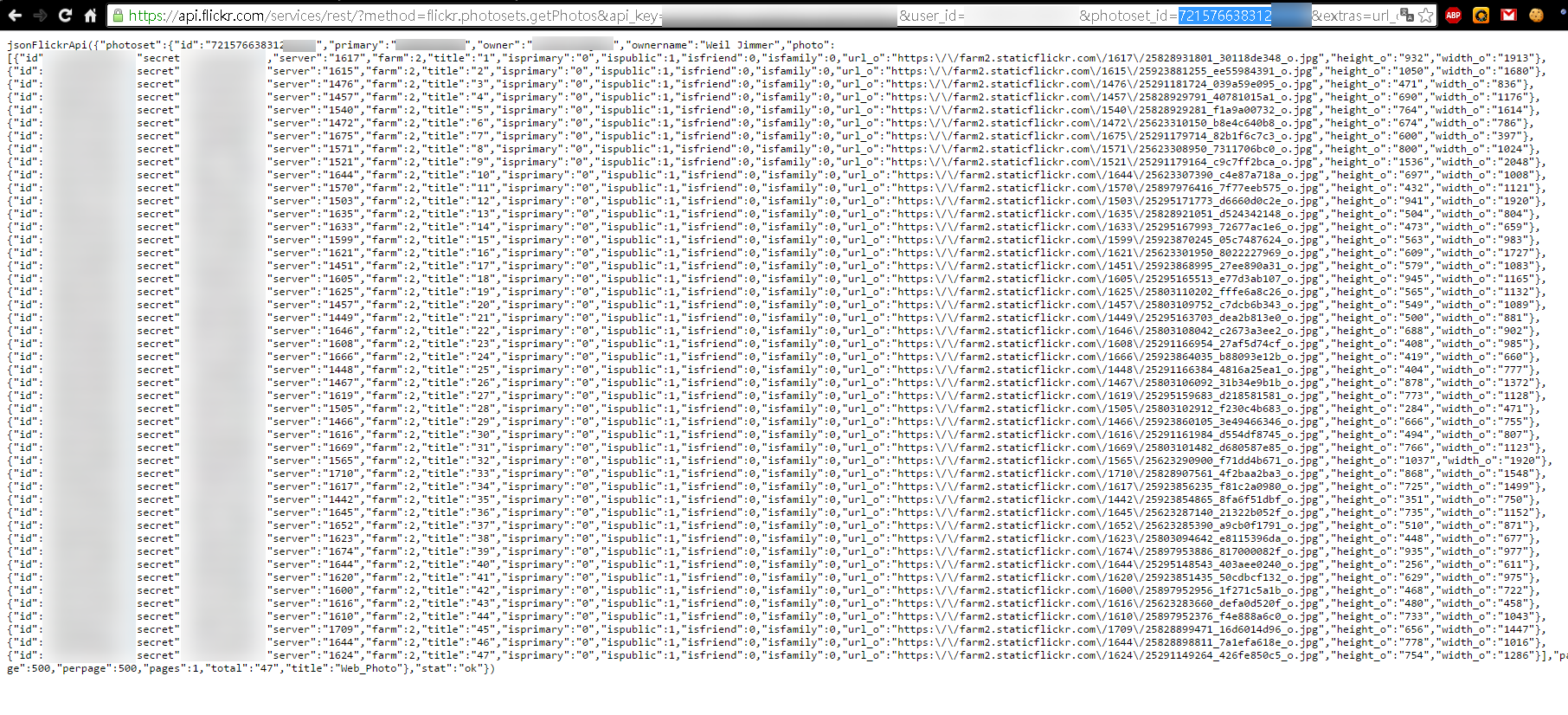
https://api.flickr.com/services/rest/?method=flickr.photosets.getPhotos&api_key={API_KEY}&user_id={USER_ID}&photoset_id={PHOTOSET_ID}&extras=url_o&format=json
就可取得 原始 資料。
範例程式碼:
<textarea name="contents" id="contents" style="resize:vertical;height:150px;font-size:12pt;"></textarea>
<script type="text/javascript">
var http = new XMLHttpRequest("Microsoft.XMLHTTP");
var url_='https://api.flickr.com/services/rest/?method=flickr.photosets.getPhotos&api_key={API_KEY}&user_id={USER_ID}&photoset_id={PHOTOSET_ID}&extras=url_o&format=json';
function connect(){
http.onreadystatechange = function(){
if (http.readyState==4){
if (http.status==200){
var str = http.responseText.toString();
str = str.substring(14,str.length-1);
var obj = JSON.parse(str);
var html_code_to_load = "";
for (var i=0;i<obj['photoset']['photo'].length;i++){
html_code_to_load += obj['photoset']['photo'][i]['url_o'] + "\n";
}
document.getElementById('contents').innerHTML=html_code_to_load.substring(0,html_code_to_load.length-1);
}else{
//Connect Failed.
}
}
}
http.open("GET",url_,true);
http.send();
}
connect();
</script>
WeilsNetLogo
This entry was posted in General, Experience, Functions, HTML, JS, XML By Weil Jimmer.
-
2016-02-25 18:25:08更新於 2017-03-04 14:49:16
- 本站自2016.02.22日起正式搬遷其域名由0000.twgogo.org更替為www.00wbf.com。
- 並且更換網站主機為專屬虛擬主機。若您還依舊使用舊網域者,請更新您的網址,謝謝。
- 本站今年5月9日至5月12日遭受DDOS巨大攻擊,導致下線,造成困擾,請見諒!
###2017.02.27-更新-###
本站最新之域名為:weils.net
WeilsNetLogo
This entry was posted in Announcement, General By Weil Jimmer.






 Linode
Linode





{kind=link}