現代已是資訊豐富多元的時代,不像以前得依靠郵差去送信,只要寄送電子郵件,幾乎瞬間就可以傳遞到對方的手上。Email也問世幾十年,但當初沒有設計好,現在才有一堆新的政策補強Email的缺點。
我直接進入正題,若有誤還請多多包涵或留言糾正我。
首先,我想先簡單介紹,Email郵件的格式,Email很像一個正常的網頁回應,包含標頭,內容,標頭Header會含有一些重要資訊,例如誰寄信的、收件者是誰、郵件的編碼、發件人IP(非必要)……資訊。通常內容是用Base64編碼啦。少數HTML郵件,是直接傳送 plaintext 純文本 UTF8 編碼郵件。郵件編碼設定有誤可能會造成收件亂碼或是軟體不支援此編碼的各種問題。
以下是範例郵件內容:
Mime-Version: 1.0
Date: Mon, 10 Apr 2017 12:59:53 +0000
Content-Type: multipart/alternative;
boundary="--=_RainLoop_611_240864755.1491829193"
Message-ID: <fc76c3e9a9187fd5b0cb8f86a8f119b8@weils.net>
X-Mailer: RainLoop/1.11.0.203
From: "Weil Jimmer" <me@weils.net>
Subject: test
To: weil@00wbf.com
----=_RainLoop_611_240864755.1491829193
Content-Type: text/plain; charset="utf-8"
Content-Transfer-Encoding: quoted-printable
--=0A=0AWeil Jimmer , Member Of White Birch Forum Team.=0Ahttps://www.wbf=
tw.org (https://www.wbftw.org/)=0A=0ABest Regards.
----=_RainLoop_611_240864755.1491829193
Content-Type: text/html; charset="utf-8"
Content-Transfer-Encoding: quoted-printable
<!DOCTYPE html><html><head><meta http-equiv=3D"Content-Type" content=3D"t=
ext/html; charset=3Dutf-8" /></head><body><div data-html-editor-font-wrap=
per=3D"true" style=3D"font-family: arial, sans-serif; font-size: 13px;"><=
signature><br><br>--<br><br>Weil Jimmer , Member Of White Birch Forum Tea=
m.<br><a target=3D"_blank" rel=3D"noopener noreferrer" href=3D"https://ww=
w.wbftw.org/">https://www.wbftw.org</a><br><br>Best Regards.</signature><=
/div></body></html>
----=_RainLoop_611_240864755.1491829193--郵件講完了,之後就是Email格式。
全世界 Email以 username@domain.net 為主,想必大家都知道這個形式也看過很多次,根據RFC標準,Email地址有效長度上限是254字串。而 「@」之後的文字為域名,就是網域名稱,通常對應的域名可能包含mail關鍵字,而且盡可能的越短越好(畢竟使用者不會記那麼長的Email)。例如:gmail.com、yahoo.com、weils.net。
講到域名就得扯到 DNS (Domain Name System),這邊簡單介紹就好了,由於現行網路世界,記憶英文單字的網址比記憶IP更來的人性化,才出了一個域名系統,瀏覽網頁都要透過查詢域名IP以對應目標伺服器才可以上網,同理,Email也是如此,Email域名透過查詢MX紀錄,得知"優先順序"及"目標伺服器IP或另一個域名"。
如圖:
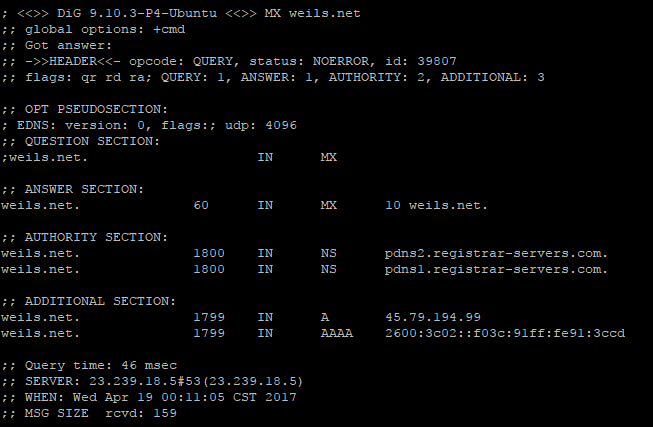
得到正確的 IP 之後,透過 TCP 連線,連到目標伺服器的 SMTP (port25或587)軟體,進行通訊作業。
可以參考看看我寫的這篇文章:不用寄信 檢查 Email 是否 真實 存在 PHP
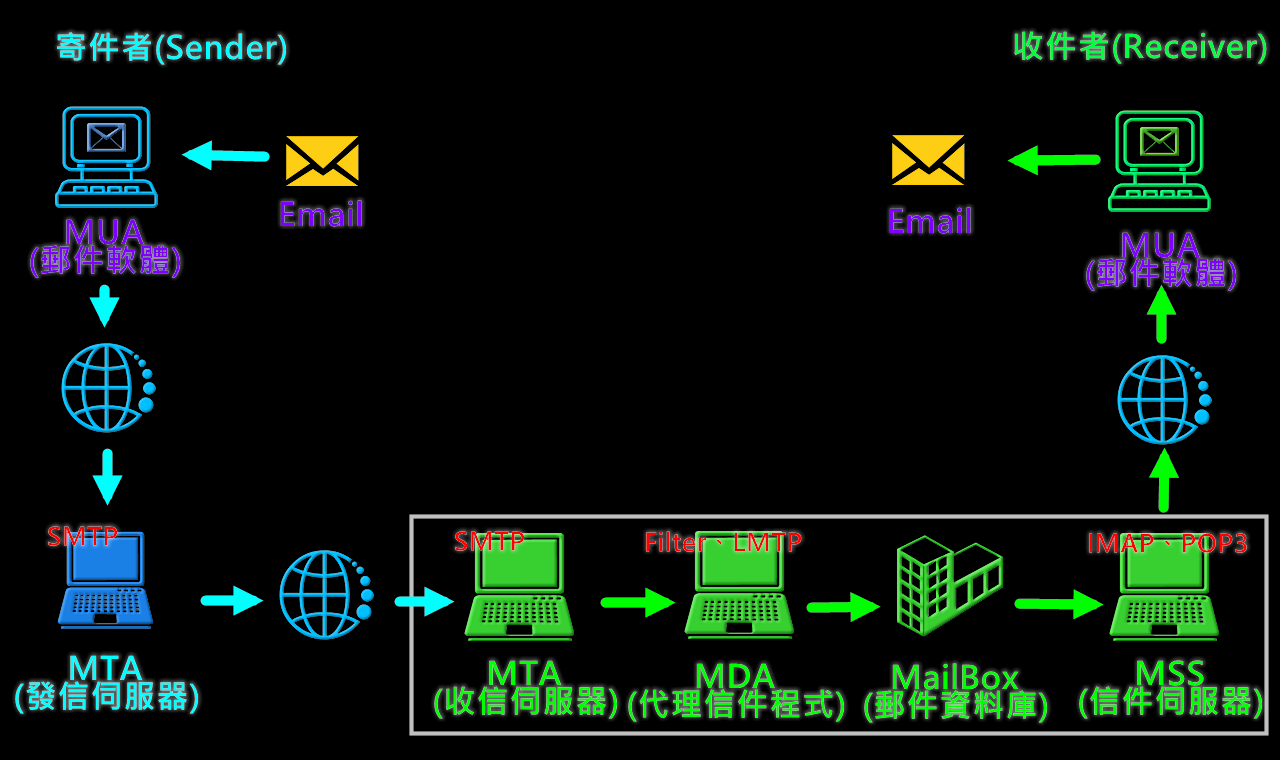
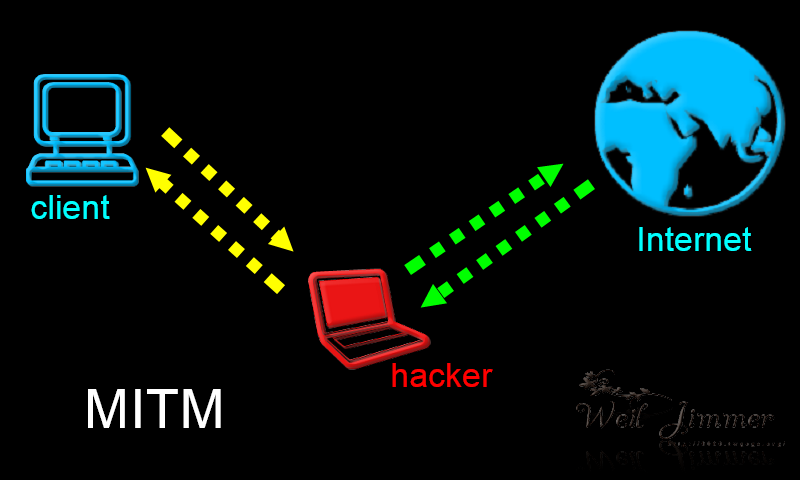
這是整個 Email 通訊的流程,透過連線到發信伺服器,然後,發到另一台收件伺服器,通過內送信件軟體存到資料庫,然後透過IMAP或POP3的形式傳出來。當然現行有更安全的通訊協定,經過TLS加密的IMAPS、POP3S,以及SMTPS…等,其中也有驗證證書,暫且不提,要談到安全連線可以參考我之前寫的文章:淺談 HTTP、HTTPS、HSTS 安全 MITM、SSLStrip
這大概就是收發信的完整流程,一些人會在內送伺服器軟體上加入過濾程式、掃描病毒,如:SpamAssassin。
我再補充一些關於IMAP(Internet Message Access Protocol)、POP3(Post Office Protocol)的區別。IMAP簡言之就是會同步Email伺服器的各種動作,在多個裝置同步登入讀取訊息,郵件也是儲存在伺服器上面。而POP3則會將郵件下載到本機的空間,並且從伺服器上面刪除,導致只有第一次取信的客戶端可以拿到信件,其餘都無法取信,因為已經被刪掉了,由於是存在本機,所以是不占用太多伺服器空間,除非一直不去取信。舉例:手機登入POP3伺服器讀取訊息,電腦版再登入電腦版的郵件軟體,是看不到那則訊息的,但假如是用IMAP,則兩台裝置都可以看到信件,並且其中一台已讀,另一台也會跟著已讀。
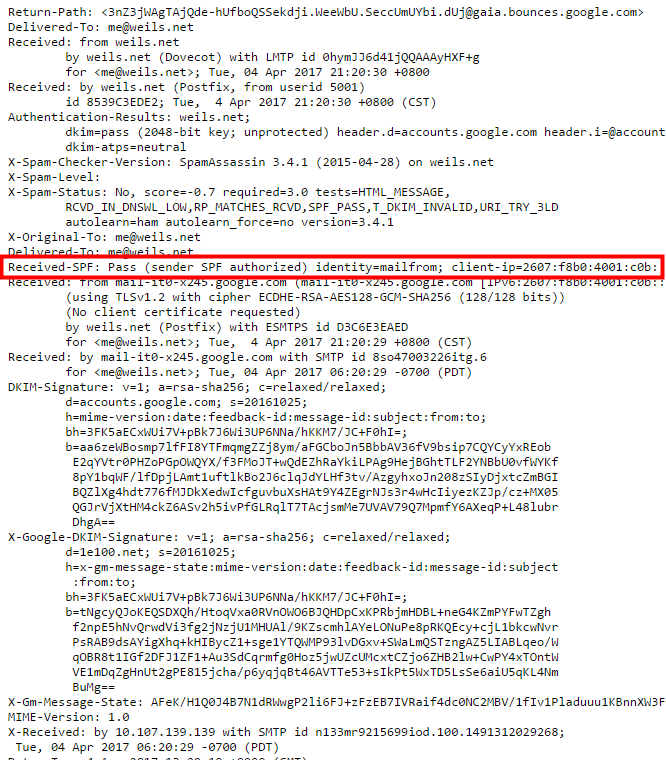
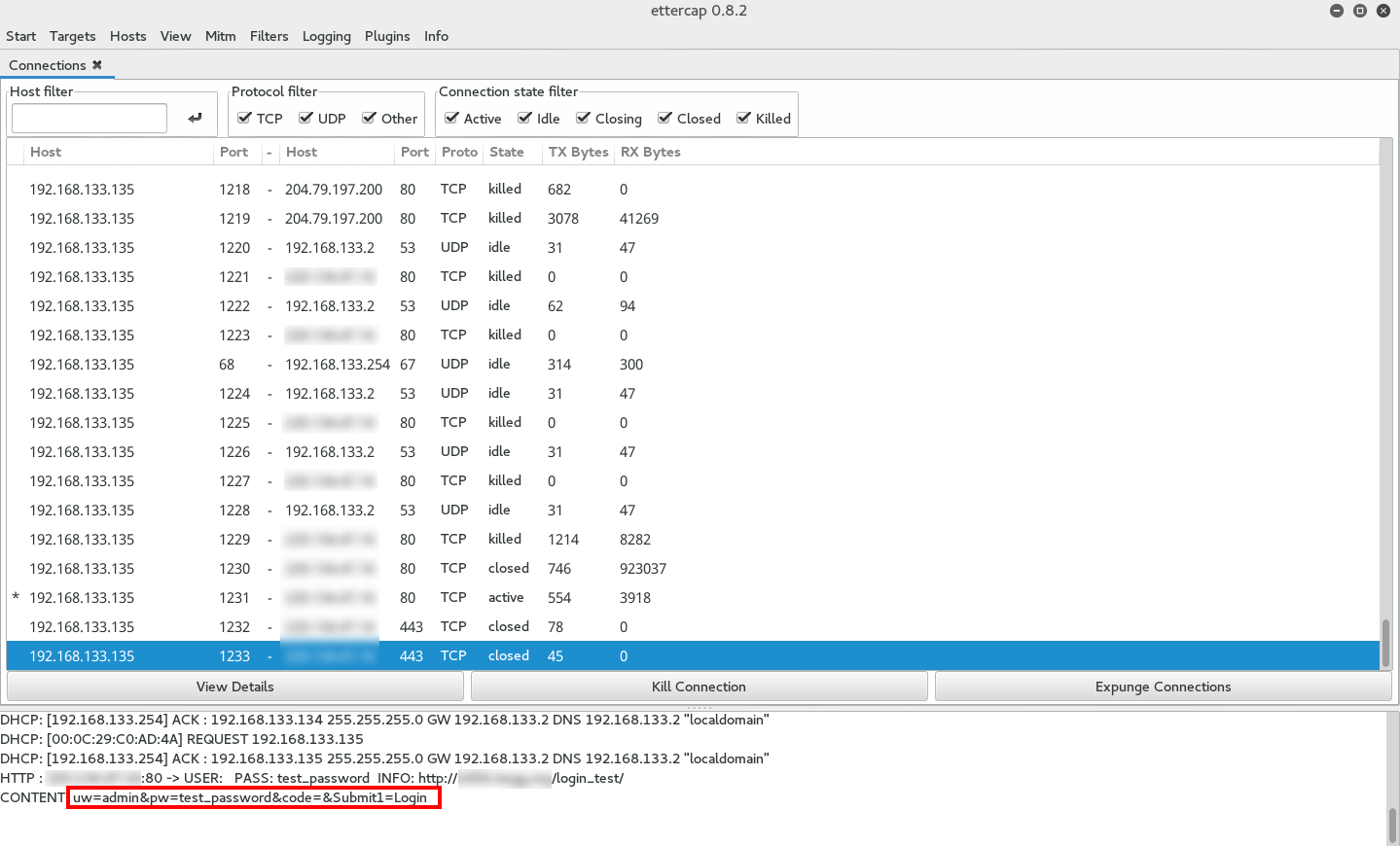
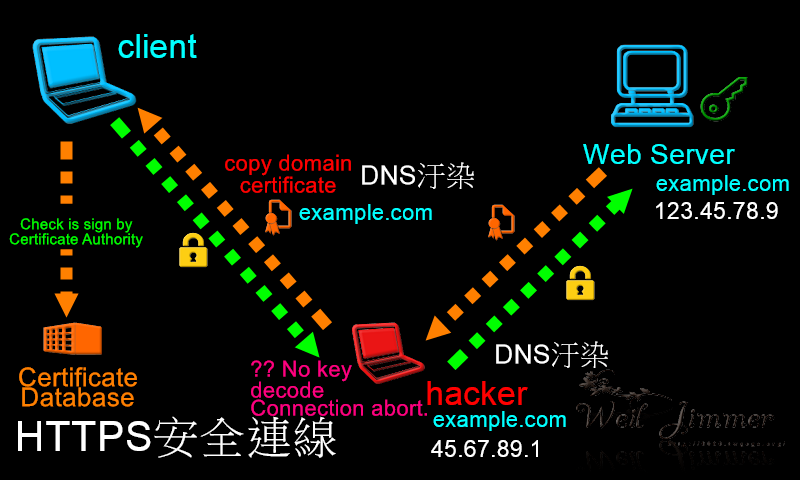
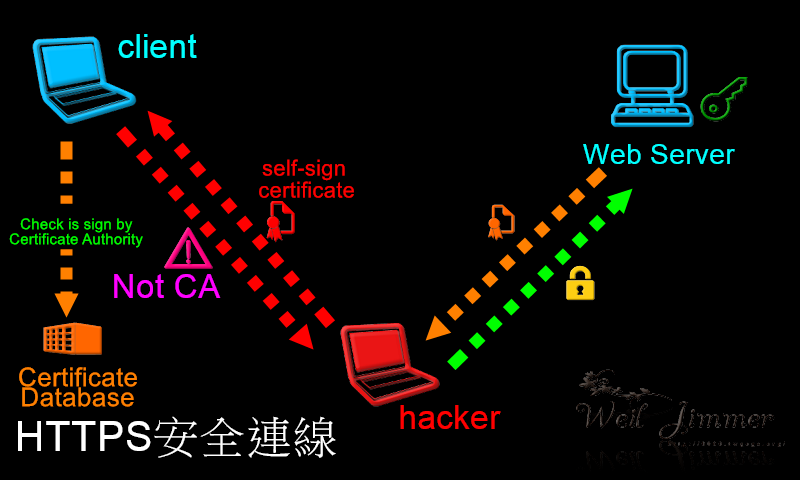
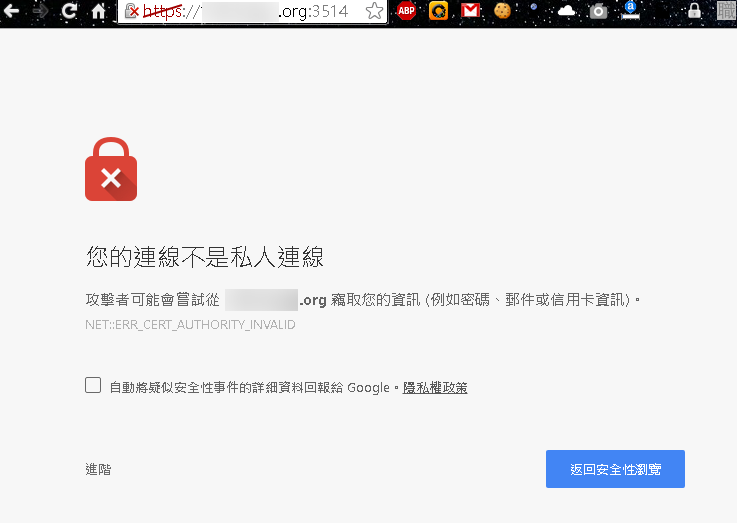
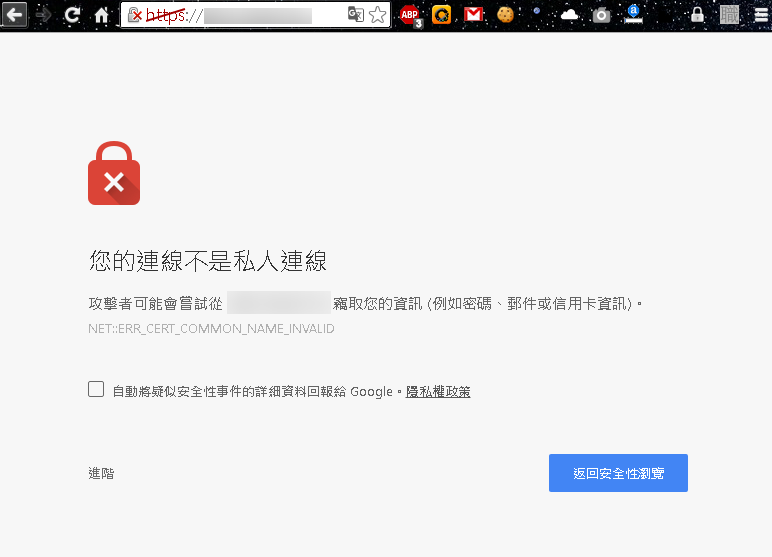
這大概就是完整的 Email 體系,但還是有安全問題。如果要講監聽的風險,很多軟體都會寫明是否驗證Email伺服器的CA證書,不過大多數預設都是忽略的,即使證書錯誤,依舊照常登入收信寄信,這給了駭客一個機會竊取 Email 資訊,另外一個安全問題就是:"發件者"是可以被偽造的!如下圖所示:
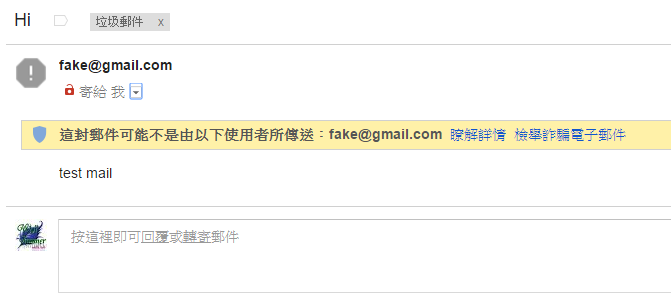
甚至發件人可以濫用發件伺服器,任何沒有設定權限(Relay Access)的伺服器都可能被拿來當作群發伺服器,發送一堆垃圾信以及偽造信件。
基於這個原因,現在的 Mail 系統,又加了一個新的技術就是DKIM,為了杜絕未經簽署,無法判斷是不是對方寫的真實信件,而不是偽造的。這整個政策主要就是,在域名key加入一個selector,裡面包含DKIM加密公鑰。
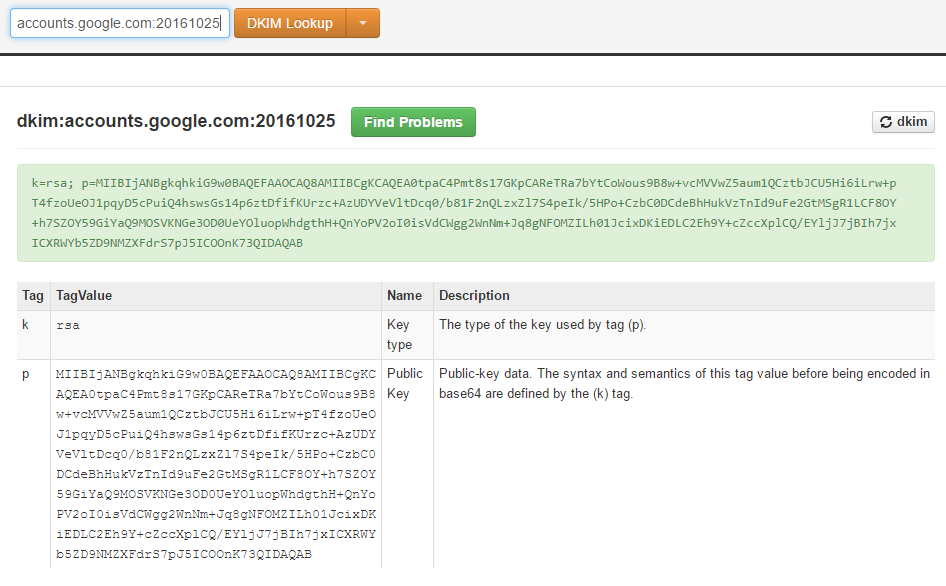
並把簽章的資訊附在郵件上面,
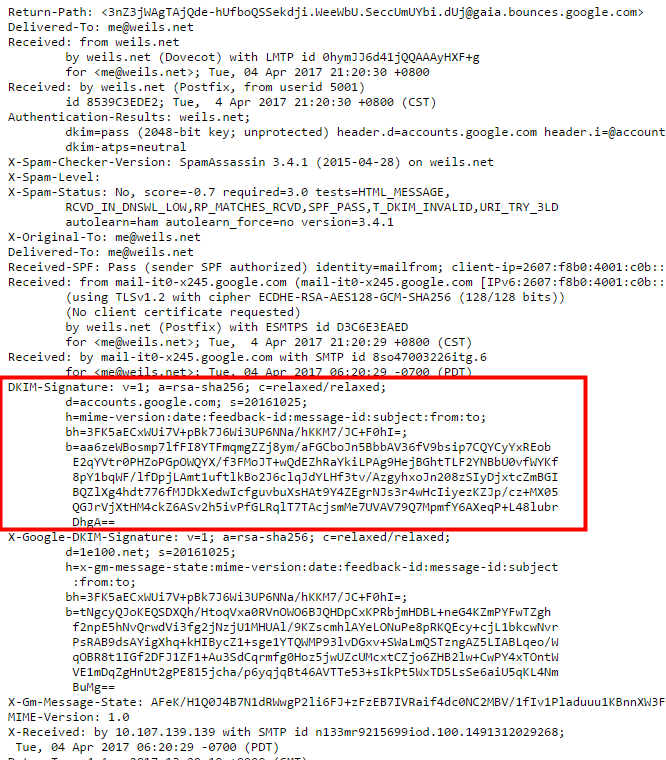
如果通過驗證,大多數郵件軟體則會顯示勾勾或任何已驗證的標示,Gmail則會顯示此郵件的簽署者。由此可以確保信件是由"特定域名"的"官方伺服器"寄出的,不是其他假的伺服器偽造出來的信件。

但,如果有其他來信是沒有簽章的,是否要信任該信件呢?這又牽扯到一個新的政策就是Author Domain Signing Practices (ADSP),一樣通過domainkey,宣告一個TXT紀錄確保所有郵件都是有簽章的!
_adsp._domainkey.example.com. IN TXT "dkim=all"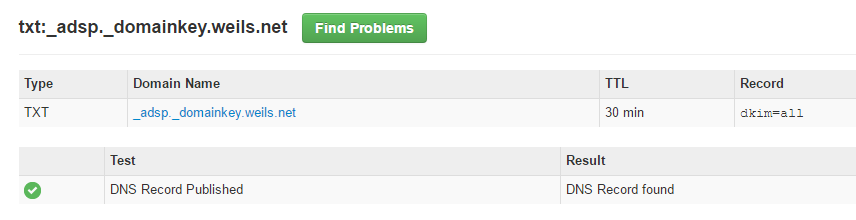
基本上,啟動 DKIM 就已經很安全了,不過基於設置上很麻煩,有另一個方法也不錯就是SPF紀錄(Sender Policy Framework (SPF)),確保發信伺服器的IP,只能由是哪些允許的IP。
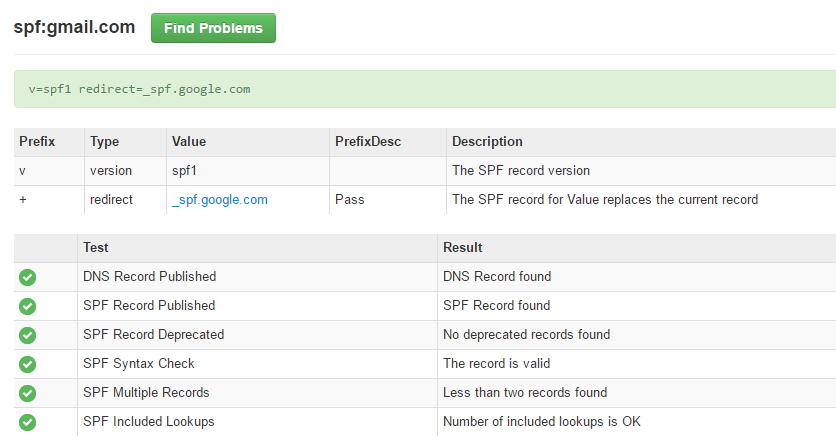
如此一來,過濾垃圾信的軟體就更好計分了,沒通過DKIM簽章,沒有加密,SPF紀錄不合的,沒有對應 hostname 的伺服器一律黑單。這些政策使得用戶能夠受到更好的保護,而不會被偽造的假信所欺騙。
基於並非所有收件伺服器都很嚴謹的過濾掉信件,所以還有一個DMARC政策,給域名管理者一個更方便的方式管理其他假的發件人。
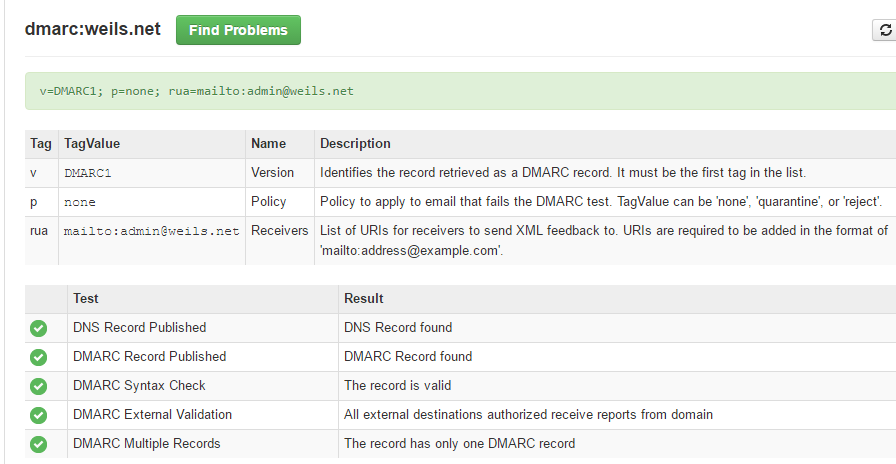
DMARC可以控制:那些沒有通過驗證的郵件是否被接受,以及,收件伺服器可以發送每日收件報告給域名管理者…等功能。以確保域名不會因被其他人濫發郵件而被列為黑單。
以下是我收到的每日回報的郵件。
附件的內容大概長這樣,
<?xml version="1.0" encoding="UTF-8" ?>
<feedback>
<report_metadata>
<org_name>google.com</org_name>
<email>noreply-dmarc-support@google.com</email>
<extra_contact_info>https://support.google.com/a/answer/2466580</extra_contact_info>
<report_id>4041210869707717010</report_id>
<date_range>
<begin>1491523200</begin>
<end>1491609599</end>
</date_range>
</report_metadata>
<policy_published>
<domain>weils.net</domain>
<adkim>r</adkim>
<aspf>r</aspf>
<p>none</p>
<sp>none</sp>
<pct>100</pct>
</policy_published>
<record>
<row>
<source_ip>2600:3c02::f03c:91ff:fe91:3ccd</source_ip>
<count>4</count>
<policy_evaluated>
<disposition>none</disposition>
<dkim>pass</dkim>
<spf>pass</spf>
</policy_evaluated>
</row>
<identifiers>
<header_from>weils.net</header_from>
</identifiers>
<auth_results>
<dkim>
<domain>weils.net</domain>
<result>pass</result>
<selector>email</selector>
</dkim>
<spf>
<domain>weils.net</domain>
<result>pass</result>
</spf>
</auth_results>
</record>
<record>
<row>
<source_ip>45.79.194.99</source_ip>
<count>1</count>
<policy_evaluated>
<disposition>none</disposition>
<dkim>pass</dkim>
<spf>pass</spf>
</policy_evaluated>
</row>
<identifiers>
<header_from>weils.net</header_from>
</identifiers>
<auth_results>
<dkim>
<domain>weils.net</domain>
<result>pass</result>
<selector>email</selector>
</dkim>
<spf>
<domain>weils.net</domain>
<result>pass</result>
</spf>
</auth_results>
</record>
</feedback>
既然都有了這麼多保護用戶的政策,用戶是否就可以安全無疑地使用 Email 呢?我想說的是:理論上沒錯,但是 Email 仍然不可以當作"隱私"的儲藏所。
Gmail會有自動機器人讀取你的電子郵件,試著找出任何違法的內容並且自動送交給相關司法機構,你可以相信 Email 服務商不會賣你的資料嗎?MailBox通常是不會加密的,網路上有一家公司提供安全的 Email服務可以參考一下(ProtonMail),正因如此,一般用戶是不可以透過 Email寄送任何敏感訊息!越正規的公司越會禁止任何違法活動,如果要安全的傳送資料,還是使用較具有隱私性的服務,或是私人Mail,基於這個緣故,現在有人推倡使用PGP加密Email。
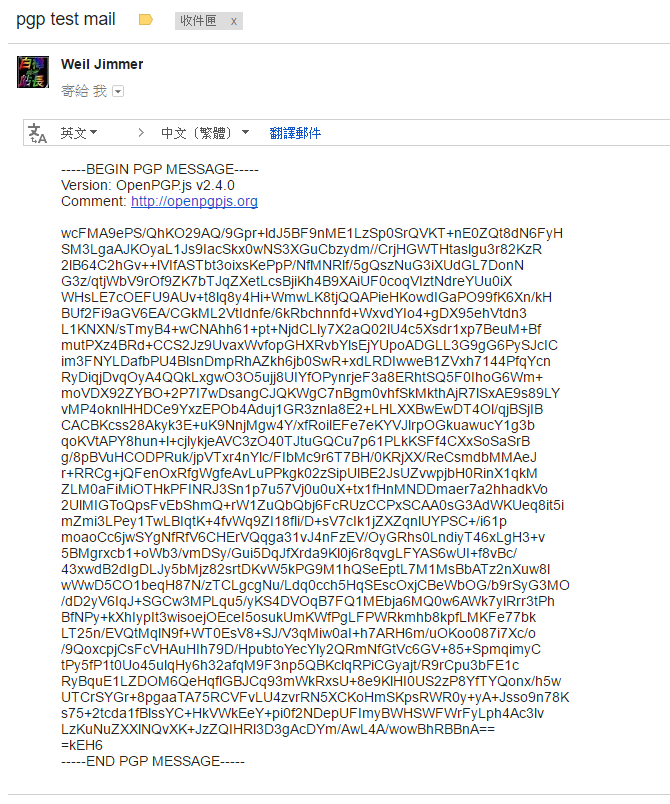
利用PGP加密的Email,沒有私鑰以及密碼是無法解密!如下圖:
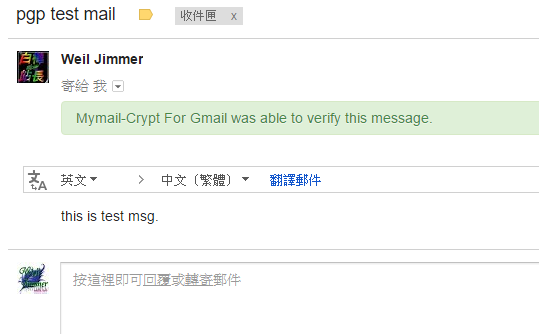
而收件人因為擁有自己的私鑰所以可以解密。如下圖:(Gmail擴展功能:PGP)
使用PGP加密的軟體,輸入一組自訂的密碼,會產生公鑰(Public Key)、私鑰(Private Key),通常我們會為了方便,把私鑰公鑰一塊存在別人的伺服器裡面,但是別擔心私鑰被儲存不安全,因為私鑰有透過加密,必須輸入當初自訂的密碼,才可以解密。
所以,要解密必須擁有密碼和私鑰。要加密,則要擁有對方的公鑰,有點類似用對方的鎖頭鎖住盒子,再寄給對方,對方必須擁有鑰匙才可以打開盒子。
同時也可以用這個方法對自己寄出的信件進行數位簽章(Sign),如此一來可以確認雙方的通訊絕對安全之外,也可以確保發信人確實就是對方,因為只有對方知道密碼。
大概介紹完了,我有想到其他的我再補充。










 Linode
Linode





{kind=link}