
我做了一個很簡單的計時器,為了某群組裡面的高中生而設計,這也是我首次製作 tg 的機器人。我才做兩個而已,所以有些功能我真的不知道的我也沒辦法為您解答。
以下是講我的經歷:
首先必須先註冊個telegram帳號(廢話),然後搜索聯繫人@BotFather 這很重要,加入這個機器人之後,首先輸入:/newbot ,然後再輸入你想要取的名子(可以是中文),接著系統會提示你再輸入用戶名稱,結尾必須是 bot ,而且僅英文數字以及下畫線,接著你的機器人就創立了,BotFather會告訴你,你的Token,這很重要,因為等下傳送或是接收訊息都要用到這組文字。
開始就是程式設計的部分,我個人是比較熟PHP,所以用PHP開發。而且還是改寫自官方的腳本。但我現在已經明白原理了。
<?php
define('BOT_TOKEN', 'BotFather給你的Token');
define('API_URL', 'https://api.telegram.org/bot'.BOT_TOKEN.'/');
//這些AppFunction和處理資料有關係,我是覺得直接Copy就好了。
function apiRequestWebhook($method, $parameters) {
if (!is_string($method)) {
error_log("Method name must be a string\n");
return false;
}
if (!$parameters) {
$parameters = array();
} else if (!is_array($parameters)) {
error_log("Parameters must be an array\n");
return false;
}
$parameters["method"] = $method;
header("Content-Type: application/json");
echo json_encode($parameters);
return true;
}
function exec_curl_request($handle) {
$response = curl_exec($handle);
if ($response === false) {
$errno = curl_errno($handle);
$error = curl_error($handle);
error_log("Curl returned error $errno: $error\n");
curl_close($handle);
return false;
}
$http_code = intval(curl_getinfo($handle, CURLINFO_HTTP_CODE));
curl_close($handle);
if ($http_code >= 500) {
// do not wat to DDOS server if something goes wrong
sleep(10);
return false;
} else if ($http_code != 200) {
$response = json_decode($response, true);
error_log("Request has failed with error {$response['error_code']}: {$response['description']}\n");
if ($http_code == 401) {
throw new Exception('Invalid access token provided');
}
return false;
} else {
$response = json_decode($response, true);
if (isset($response['description'])) {
error_log("Request was successfull: {$response['description']}\n");
}
$response = $response['result'];
}
return $response;
}
function apiRequest($method, $parameters) {
if (!is_string($method)) {
error_log("Method name must be a string\n");
return false;
}
if (!$parameters) {
$parameters = array();
} else if (!is_array($parameters)) {
error_log("Parameters must be an array\n");
return false;
}
foreach ($parameters as $key => &$val) {
// encoding to JSON array parameters, for example reply_markup
if (!is_numeric($val) && !is_string($val)) {
$val = json_encode($val);
}
}
$url = API_URL.$method.'?'.http_build_query($parameters);
$handle = curl_init($url);
curl_setopt($handle, CURLOPT_RETURNTRANSFER, true);
curl_setopt($handle, CURLOPT_CONNECTTIMEOUT, 5);
curl_setopt($handle, CURLOPT_TIMEOUT, 60);
return exec_curl_request($handle);
}
function apiRequestJson($method, $parameters) {
if (!is_string($method)) {
error_log("Method name must be a string\n");
return false;
}
if (!$parameters) {
$parameters = array();
} else if (!is_array($parameters)) {
error_log("Parameters must be an array\n");
return false;
}
$parameters["method"] = $method;
$handle = curl_init(API_URL);
curl_setopt($handle, CURLOPT_RETURNTRANSFER, true);
curl_setopt($handle, CURLOPT_CONNECTTIMEOUT, 5);
curl_setopt($handle, CURLOPT_TIMEOUT, 60);
curl_setopt($handle, CURLOPT_POSTFIELDS, json_encode($parameters));
curl_setopt($handle, CURLOPT_HTTPHEADER, array("Content-Type: application/json"));
return exec_curl_request($handle);
}
//上面的程式碼都建議直接Copy拿來用
//我自己的程式碼開始
$target_times=1465772400;
$msg = '距離【畢業典禮】還有'."\n".floor(($target_times-time())/86400).'天'.floor((($target_times-time())%86400)/3600).'時'.floor(((($target_times-time())%86400)%3600)/60).'分'.(((($target_times-time())%86400)%3600)%60).'秒!';
if (time()>$target_times){
$msg="";
}
$target_times=1467327600;
$msg .= "\n".'距離【指考】還有'."\n".floor(($target_times-time())/86400).'天'.floor((($target_times-time())%86400)/3600).'時'.floor(((($target_times-time())%86400)%3600)/60).'分'.(((($target_times-time())%86400)%3600)%60).'秒!';
if (time()>$target_times){
$msg="";
}
//處理開始函數,傳入$msg是因為我這個程式的功能所需,並非必要
function processMessage($message,$msg) {
// process incoming message
$message_id = $message['message_id'];
$chat_id = $message['chat']['id'];
if (isset($message['text'])) {
// incoming text message
$text = $message['text'];
if ($text === "/start" or $text === "/start@botusername"){
if ($msg!=""){
apiRequestJson("sendMessage", array('chat_id' => $chat_id, "text" => $msg."\n聊天室ID:".$chat_id));
}
} else if ($text === "/show" or $text === "/show@botusername") {
if ($msg!=""){
apiRequestJson("sendMessage", array('chat_id' => $chat_id, "text" => $msg));
}
} else if (strpos($text, "/stop") === 0) {
// stop now
} else {
// 其他指令或訊息
}
}
}
if (php_sapi_name() == 'cli') {
// if run from console
//這是為了定時任務的區別,如果是從Crontab跑,就從這邊
if ($msg!=""){
apiRequestJson("sendMessage", array('chat_id' => '00000000000', "text" => $msg));
}
exit;
}
$content = file_get_contents("php://input"); //讀取資料 (In)
$update = json_decode($content, true); //JSON解析
if (!$update) {
// receive wrong update, must not happen
// 接收到錯誤訊息
exit;
}
if (isset($update["message"])) {
//接收到正確訊息,調用處理函數
processMessage($update["message"],$msg);
}
程式碼都獻上了,現在開始講原理。
首先必須要有一台服務器,來執行WebHook,把你寫好的PHP檔案上傳到伺服器上面,注意檔名最好建立很特殊的名稱,讓一般使用者無法猜到你用什麼檔名,以預防惡意人士直接訪問你的程式。(洪水轟炸,或偽造請求之類的。)
上傳後,請直接訪問 https://api.telegram.org/bot{TOKEN}/?method=setWebhook&url=https://www.example.com/{secret}bot.php
例如:
https://api.telegram.org/bot123456789:AAAAAAAAAAAAAAAAAAAAAA/?method=setWebhook&url=https://www.example.com/secret_random_path/bot.php
參數url後面接的就是你要接收的位置,僅支援https,完畢後一旦直接對bot講話輸入指令,telegram就會立刻送出對話內容傳到你的程式,而你的程式處理完之後再回傳給telegram,這就是它的工作原理。
得到的內容長得像:(已經被解析的Object["message"])
(
[message_id] => 01
[from] => Array
(
[id] => 123456789
[first_name] => Nickname
[username] => username
)
[chat] => Array
(
[id] => -123456789
[title] => test
[type] => group
)
[date] => 1464504645
[text] => /say I just say?
[entities] => Array
(
[0] => Array
(
[type] => bot_command
[offset] => 0
[length] => 17
)
)
)
簡單明瞭,這只是message的部分,有可能會出現其他資料,例如傳圖片,有人加入群組時,就會不同了,請參閱 telegram 文檔,https://core.telegram.org/bots/api。
而我的設計是當使用者輸入 /start 時,就會回傳 聊天室 id,因為我需要 id 才可以讓我直接發訊息回去,否則必須每次都是被動型傳輸,這樣我就可以主動傳送了,因為我不需要依靠對方先傳訊息給我才可以取得 id 回傳。
而我設定輸入指令 /show 時 就會彈出距離目標時間還有多久。而且利用 cron job 定時任務,每天都會 run 這程式發送一次倒數訊息。這就是整個簡單的概念。
接下來,在 tg 上就可以直接操作並直接顯示結果了,唯一缺陷就是沒有指令選單。這時可以再向 BotFather設定,輸入 /setcommands,再輸入 @botname,指令(英文)+空格+簡介。(可以多行輸入)
最終預防機器人被濫用亂加入群組,可以設定鎖定,/setjoingroups → @botname → Disable。
這樣就大功告成了。其他功能自己探索,其實很簡單的。
WeilsNetLogo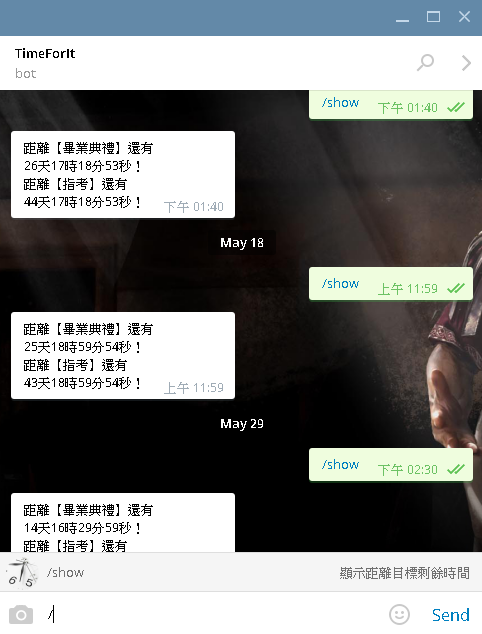







 Linode
Linode





{kind=link}