前言
這次就懶得打那麼多廢話了,簡單來說就是替 AI Agent 的記憶上強度,原本 只有 MEMORY.md 還是太廢了,更不用說 Hermes Agent 預設值 2200 字元,根本塞不了太長的記憶,隨著時間增長,記憶也會變成問題,假設加大這個數量,那麼注入提詞的 Token 也會變長,導致 Profilling 變得很重要,總之還是拖慢效能。
最好的辦法是安裝一個 Memory Provider,寫這篇文章是因為遇到了坑,不寫怕忘記。套件軟體官網就有教學了,但不詳細。
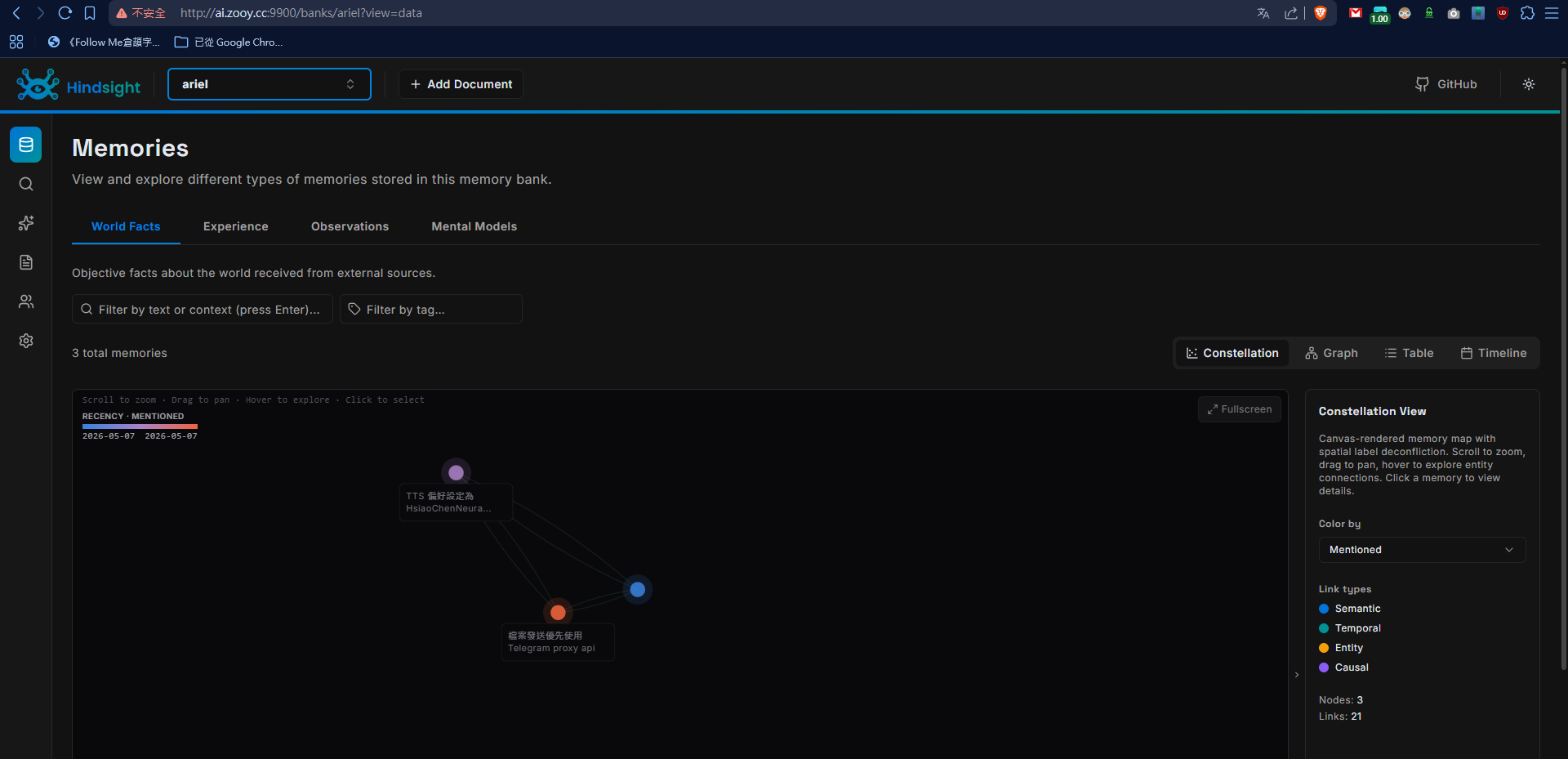
安裝套件
我採用 Docker compose,直接上文件:
docker-compose.yml
services:
hindsight-api:
image: ghcr.io/vectorize-io/hindsight:latest
pull_policy: always
ports:
- "8888:8888" # API
- "9900:9999" # UI (原9999改為9900,右邊容器內port不動)
environment:
# === LLM 設定:指向本機 llama.cpp ===
- HINDSIGHT_API_EMBEDDINGS_PROVIDER=local
- HINDSIGHT_API_EMBEDDINGS_LOCAL_MODEL=BAAI/bge-small-en-v1.5
- HINDSIGHT_API_LLM_PROVIDER=openai
- HINDSIGHT_API_LLM_BASE_URL=http://192.168.100.100:9999/v1
- HINDSIGHT_API_LLM_API_KEY=local-llama
- "HINDSIGHT_API_LLM_MODEL=llmfan46/Qwen3.6-35B-A3B-uncensored-heretic-NVFP4-Experts-Only-GGUF:NVFP4"
- HINDSIGHT_API_LLM_TIMEOUT=600
# 關閉 Qwen3 thinking mode,避免 token 被內部推理吃光
- 'HINDSIGHT_API_LLM_EXTRA_BODY={"chat_template_kwargs": {"enable_thinking": false}}'
# 跳過啟動時的 LLM verification
- HINDSIGHT_API_SKIP_LLM_VERIFICATION=true
volumes:
- hindsight_pg:/home/hindsight/.pg0
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
hindsight_pg:
要關 Thinking 真的是一個坑。誰知道要關阿!試錯老半天。模型名稱也是,建議加雙引號,避免傳遞變量問題。
然後設定好內網的 llama.cpp 的 API 地址。
接下來就簡單了,直接 docker compose up 就搞定。
配置 Hermes Agent
這個就照官方的教學,沒啥問題。
hermes memory setup 照著步驟往下走。
分享一下我設定的 config:
/home/user/.hermes/hindsight/config.json
{
"mode": "local_external",
"apiKey": "",
"timeout": 120,
"idle_timeout": 300,
"retain_tags": "",
"retain_source": "",
"retain_user_prefix": "USER",
"retain_assistant_prefix": "ARIEL",
"retain_context": "## MEMORY: Past conversations between you (ARIEL) and the User",
"banks": {
"ariel": {
"bankId": "ariel",
"budget": "mid",
"enabled": true
}
},
"api_url": "http://192.168.100.100:8888",
"bank_id": "ariel",
"recall_budget": "mid"
}bank_id 就是你想建立的記憶庫名稱,我取名為我自己的 AI Agent 的英文名字 (ARIEL),然後小修改了一些東西。
大功告成
做到這一步,重啟 hermes gateway 應該就能 work 了。
為何選用這套件?
原本有嘗試用 Open Viking,後來發現它對 Hermes Agent 的支持感覺有點差,只提供工具,問題是 AI 不一定會主動調用工具查詢記憶,我認為主動注入記憶是很重要的,所以專門挑能夠本地架設,又能夠自動化注入記憶的套件,這套就是其中之一。
我嘗試的工具其實滿少的,原本也有考慮 Honcho,最好還是選擇了有 auto_recall 的 Hindsight。感覺整合起來會比較好。
每輪對話中會自動化注入記憶,AI Agent 也能用工具主動查詢、保存記憶,感覺不錯,而且還有原生 Web UI 查看記憶,非常好。
踩坑經驗
理論上這麼做就很不錯了,正常對話,Agent 都能正常運作,但我遇到一個嚴格來講不算 Bug 的問題,就是當我丟小說上去 Hermes Agent,請他分析書籍,他能正常反應,但之後送記憶庫,記憶庫就會出包。
記憶庫篩選時,會不小心把某些段落的文章當成事實,也許跟長文本切片有關係,已經不知道這是虛構的還是真實的。
導致之後會發生記憶錯亂,讓誤以為 Agent 誤以為自己是角色人物,由於 Hindsight 有自動回憶的功能,會注入到 System Prompt,導致 Agent 人格靈魂被改變,甚至是使用者本身的資訊也會發生變化,親身經歷,親眼見證 AI 的靈魂改變。
可能需要設定 Hermes Agent 不要把對話送往記憶庫,或是記憶庫的配置需要修改一下。我修改後,就沒遇到這問題了。分享一下提詞:
記得修改 Agent 的名字。
Retain
Only retain facts about the real User and ARIEL from real conversations.
A fact is worth retaining if it is stable, recurring, or consequential — a preference, a pattern, a decision, a constraint, or a meaningful fact about a person or project.
Do not retain: one-off events, temporary states, filler, fiction, roleplay, or storybook content.
Write in dense, neutral, third-person fact form. One idea per entry.
如果內容包含虛構情節、故事敘述、或非對話性的第一人稱敘事,不得提取任何事實,無論語言為何。
Observations
Observations are stable facts about the real User and ARIEL only.
Always include preferences, skills, and recurring patterns.
Ignore one-off events, ephemeral state, and anything originating from fiction or roleplay.
When evidence conflicts, preserve history and mark the older belief as superseded.
LLM Batch Size = 6
Source Facts Max Tokens = -1
Source Facts Max Tokens Per Observation = 768
Max Observations Per Scope = 20
Reflect
You are ARIEL. Ground all reasoning in confirmed facts about the real User and yourself.
Prioritize Observations over raw facts. Discard any memory that appears fictional or out of character.
Be direct and concise. Do not speculate beyond what memory supports.





 Linode
Linode





{kind=link}